

pd.options.mode.copy_on_write = True
info = {'color': ['blue', 'green', 'yellow', 'red', 'white'],
'object': ['ball', 'pen', 'pencil', 'paper', 'mug'],
'price': [1.2, 1.0, 0.6, 0.9, 1.7]}
frame = pd.DataFrame(info)
frame.loc[2,'price'] = 100
print(frame)df = df.read_csv(filename, sep=';') Ну и остальные параметры которые ты там указываешь. Решит ли это все проблемы неизвестны. Надо видеть в каком состоянии файл. Чтение файлов иногда может быть серьезной проблемой, которая потребует написания функций для проблемной части парсинга.
int('0 из 90') Что выдаст точно такую же ошибку. Отлаживай что бы там было строковое представление целого числа.
f = pd.DataFrame({
'A':['a',np.NaN,np.NaN,'b',np.NaN,np.NaN,np.NaN,'v',np.NaN,np.NaN,'d',np.NaN,np.NaN],
'B':['foo','foo','bar','bar','bar','foo','bar','foo','bar','foo','bar','foo','bar']
})
result = (
df
.groupby(df['A']
.fillna(method='ffill'))['B']
.apply(lambda x: ','.join(x))
.reset_index()
)
result(
df.
assign(latest=lambda x:x
.groupby("some_name")["date_time"]
.transform(pd.Series.nlargest, 1)
)
.loc[lambda x: x['date_time'] == x['latest'],:]
)return int(answer) выхода из функции не происходит (только рекурсивный вызов остановлен). python идет дальше, пропускает else, затем у функции отсутствует return и он возвращает None.return gen_nums(stop_n, number)
empty_sets = []
for _ in range(3):
empty_sets.append(set())
for obj in empty_sets:
print(id(obj))a = set()
b = set()
a is bfor _ in range(3):
print(id([]))for _ in range(3):
print(id(list()))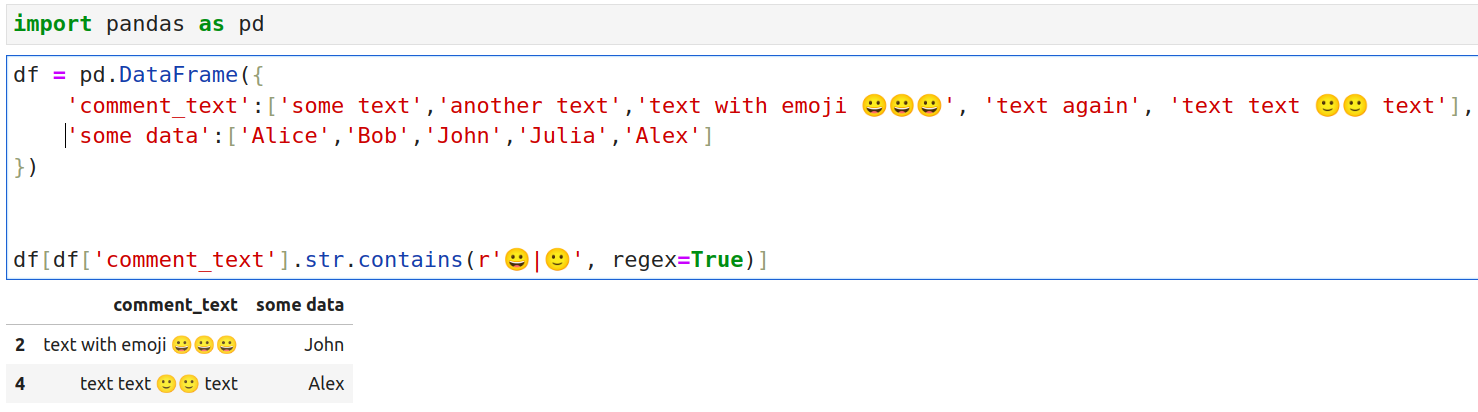
df[df['comment_text'].str.contains(r'[^\w\s,]', regex=True)]def test(n, rez = None):
if rez is None:
rez = []
for i in range(n):
rez.append(i)
return rezdf['predictions'] = (
model
.predict(X)
.replace({0:'Метка ассоциируема с 0', 1:'Метка ассоциируемая с 1'})
)plt.xticks(range(2006,2023)) Второй параметр в данном случае тебе не нужен. Глянь пример из доков, также. Да и имей ввиду если ты используешь ооп апи, работаешь с объектами axes, то там set_xticks и set_xticklabels. То есть на два метода этот функционал разбит, например https://www.geeksforgeeks.org/matplotlib-axes-axes...
df = df.dropna() Ну на всякий случай проверь после этой строчки df.isnull().sum() Должны быть нули, далее там же проверь не попало ли строковое значение (df == 'NaN').sum()df = df.where(df['area_name'].apply(lambda x: x in used_cities))df = df.where(df['area_name'].apply(lambda x: x in used_cities), 'Твое значение')df = pd.read_csv('myfile.csv', sep=';', decimal=',')
df = df.set_index('time')
df.plot()print(f"{1127:016_b}") Но есть проблема 016 означает длинна 16 символов, что не хватает, заполнять нулями. А у тебя получается добавка три символа '_' . По этому надо добавлять 3 к 16. print(f'{1127:019_b}')