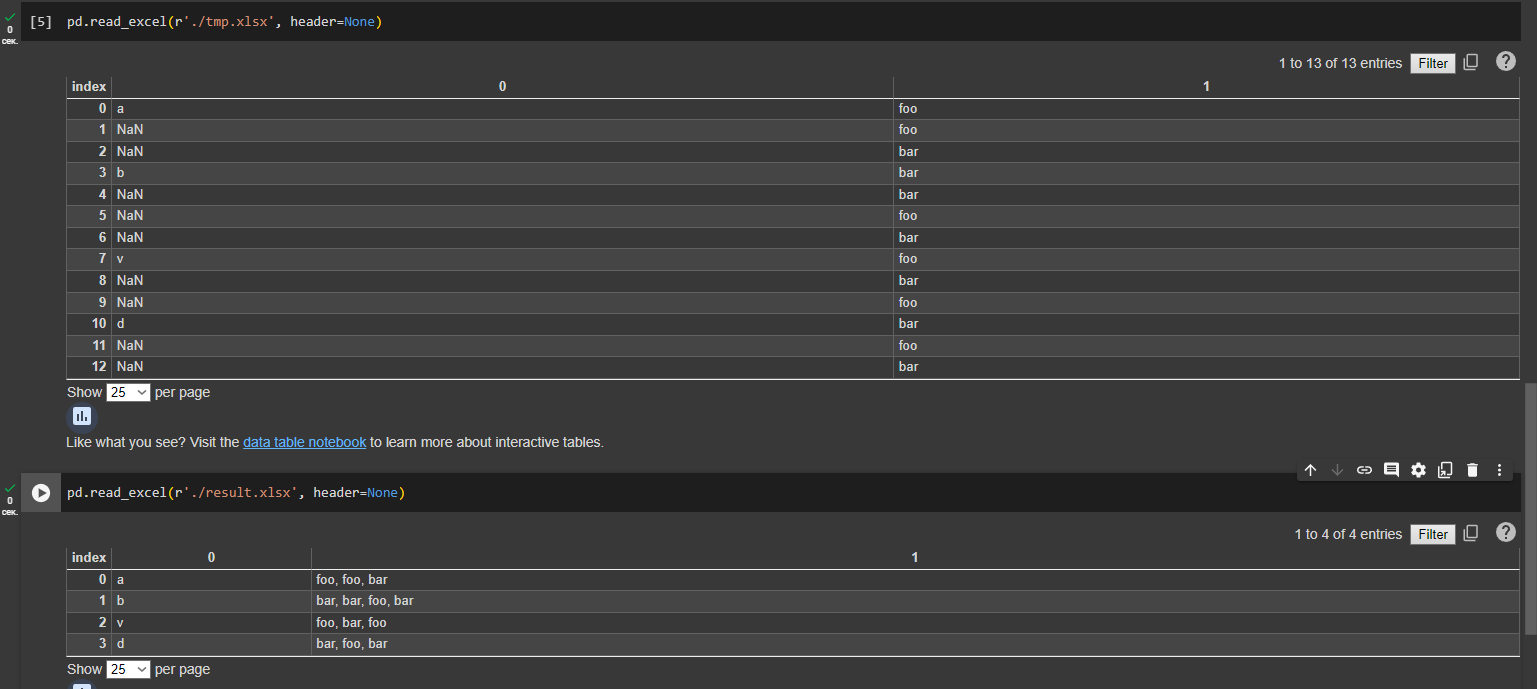
Ну на сам деле задачка на 5 минут, есть определенные методы заполнения пропущенных значений, 'ffill' forward fill и 'bfill' backward fill. Они и есть ключ к решению, далее группировка происходит без проблем, и дальнешее дело техники, при чем многими способами, например так.
f = pd.DataFrame({
'A':['a',np.NaN,np.NaN,'b',np.NaN,np.NaN,np.NaN,'v',np.NaN,np.NaN,'d',np.NaN,np.NaN],
'B':['foo','foo','bar','bar','bar','foo','bar','foo','bar','foo','bar','foo','bar']
})
result = (
df
.groupby(df['A']
.fillna(method='ffill'))['B']
.apply(lambda x: ','.join(x))
.reset_index()
)
result