Ужас нах. Вы со своим питоном делаете огромный откат в сфере десктопных решений. Возьмите нормальный язык. То что вы хотите, делается в течение 3 часов на нормальном языке. Честно. Я могу тебе дать готовое решение через 3-4 часа. Оно будет содержать exe размером в 10мб и sqlite библиотеку. Два файла. Это решение будет работать на любой винде без каких-либо предустановок и настроек.
Ну-ка, давайте сделайте мне бота, который будет кликать по кнопка на сторонней странице в игре на HTML5. И несколько легко это получится у новичка) Крайне интересно.
Сергей Горностаев, сейчас им вдалбливают, что на паскале ничего не сделаешь. И они будут правы, но ни кто им нормально не рассказывает о том, что паскаль - примитивный язык и необходимо смотреть на Delphi, а не на паскаль. И очень-очень жирный плюс в сторону питона в том, что он "простой". Он не требует знаний типизации и многие вещи там реализованы заранее, вроде неявных преобразований.
Сергей Горностаев, думаешь? А каким местом они выбирали, как думаешь? Ни каким, то что преподавали, то и берут. То что проще пишется, то и берут. А в питоне максимальная фривольность, приводящая к говнокоду.
Pascal стали меньше преподавать, т.к. на основной функциональный язык Delphi была монополия. А компания, владеющая этой монополией переживала некоторые проблемы. Если интересно, можешь где-нибудь почитать что и как и как там замешена Microsoft. Т.е. что мы в некоторый момент имели? Устаревшую среду разработки, которую компания не развивала из-за своих проблем (смена владельца, целей и прочее) и тот факт, что она была платная и не имела бесплатных редакций. Сейчас ситуация куда лучше. Текущий владелец максимально быстро навёрстывает упущенное, всего за несколько лет добавил кроссплатформенность, которую вероятно вообще мало кто имеет. Qt - кроссплатформенный, но большую часть кода под другую платформу тоже придётся писать. Остальные решения - это веб решения.
Сергей Горностаев, только вы не понимаете сути. Ни одна отрасль или компания не скажет тебе, что ей нужна программа на питоне для автоматизации каких-то процессов. Ей просто нужна программа. Ведь так? Следовательно при чем тут язык? Необходимо понимать, почему случился перекос в сторону питона или другого языка. И причина этому далеко не возможности или недостатки языка. Программы на делфи до сих пор без проблем работают в компаниях. Написанные ещё десяток лет назад без проблем работают на вин10 и будут работать дальше в новых версиях.
"Отрасли и компании" не понимают, что программы на питоне будут требовать постоянного обслуживания. Не они выбирают язык, а разработчик. И новый разработчик на его месте будет также долго разбираться в коде из десятка файлов с кодом в несколько тысяч строк. Любая новая компания будет требовать искать программиста, а не программиста питона. И уже этот программист будет выбирать язык-инструмент. И раз питонистов сейчас больше, то понятно всё становится.
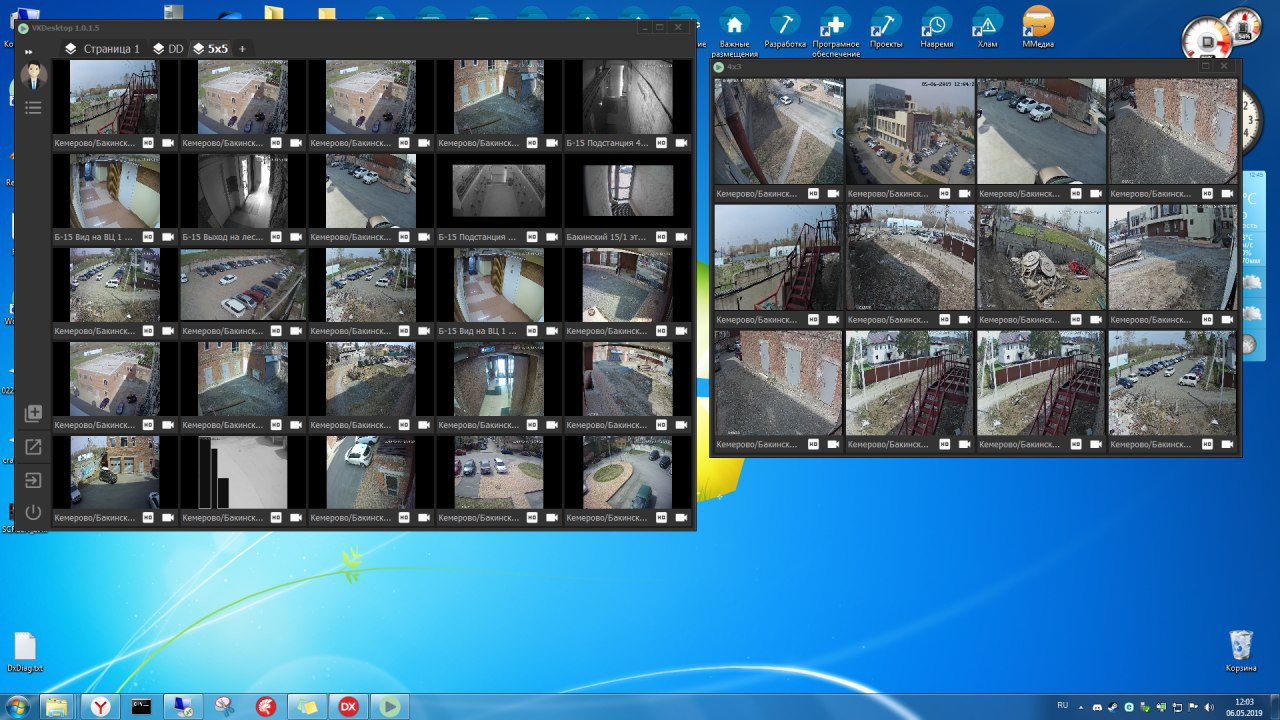
Клиент для видеоконтроля, на 64битной винде позволяет просматривать до 40 камер одновременно
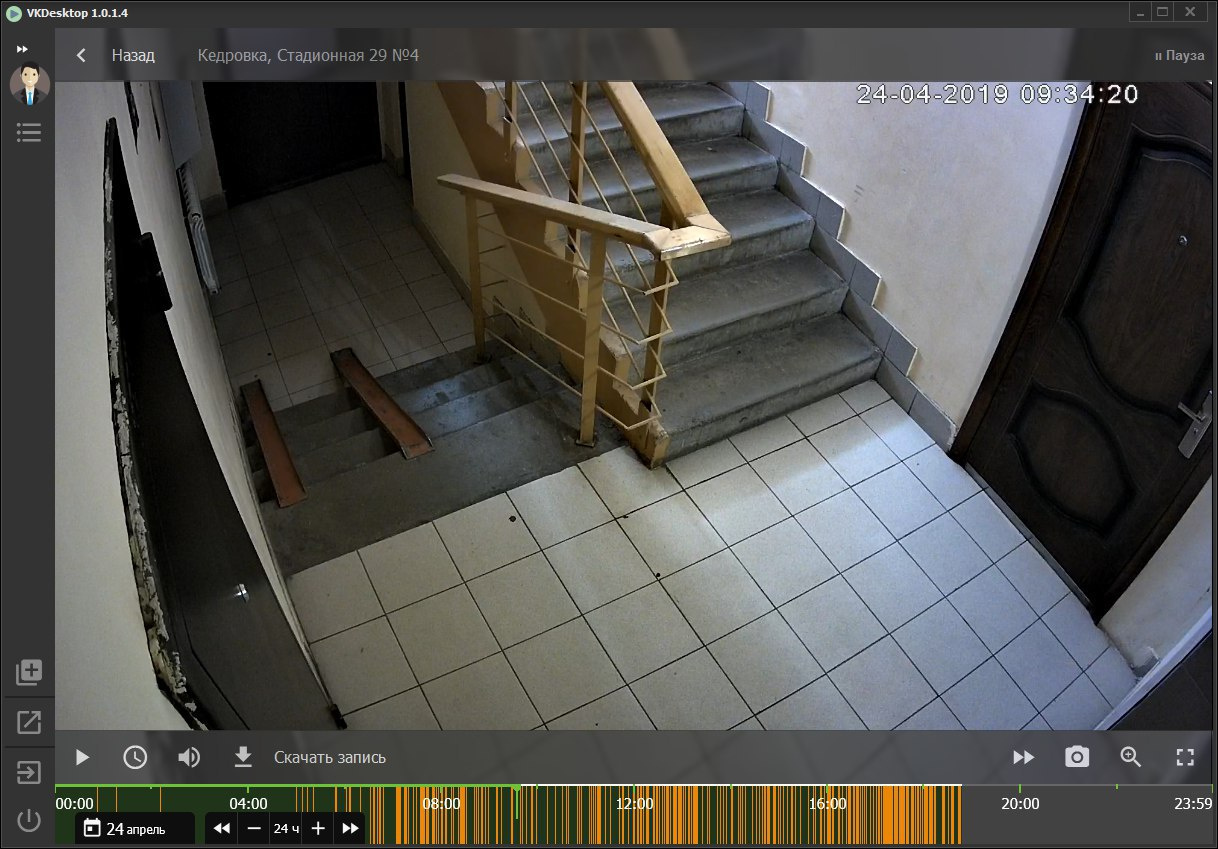
IPTV плеер с http авторизацией и видеоархивом
Тайм-менеджер
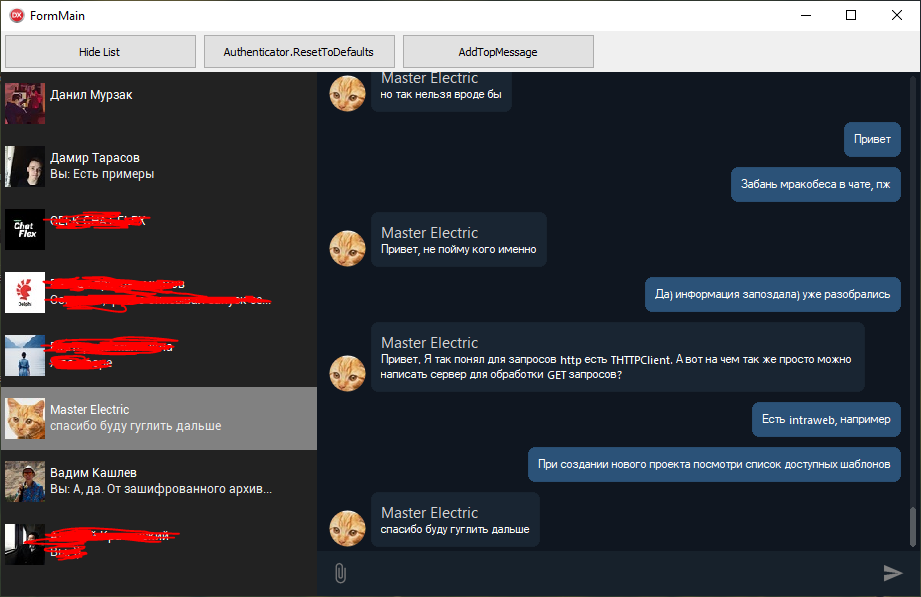
Пример работы с моей оберткой для ВК апи. Мессенджер. Кода примерно на 100 строк
Это только то, что получилось у меня быстро отыскать со скринами и только то, что написал исключительно я. А это жалкие крохи того, что можно делать с малыми затратами. Существуют масштабные фреймворки для веб разработки, существует FGX фреймворк для андроид с нативными компонентами. Существуют ORM, REST и другие фреймворки. А с фреймворком FMX можно создавать приложение одним кодом под разные платформы (все существующие популярные платформы). Т.е. достаточно выбрать платформу и нажать кнопку "Собрать", чтобы получить бинарник. При чем, все итоговые приложения не имеют зависимостей, а являются самодостаточными приложениями на каждой платформе.
BananiumPower, зачем ты сюда вообще пришел? Сказать "учите лучше питон"?
Вы нихера не понимаете, на что способен "паскаль", так что идите просто лесом, если видите теги Паскаля и Делфи. А свое мнение и языке засуньте обратно в жопу
Александр, ты снова вносишь понятие "домена" из мира ActiveDirectory в тему о DNS. Забудь о AD, домен DNS и домен AD - разные вещи. Просто называются одинаково.
"Подключиться к домену" - это значит стать частью домена. Ни кто не говорит так, говоря о подключении к хосту.
Домен DNS - это не про железо. Это исключительно про адресацию. Ни какие хосты и железо здесь не при чем. Это работает отдельно и независимо. Это таблица резолва (разрешения) имён. DNS - Domain Name System. У тебя есть имя, ты получишь соответствующий этому имени ip адрес, если он есть.
Александр, "Есть IP адрес - значит есть сетевая карта - значит есть..." - это не так. IP адрес не подразумевает наличие сетевой карты, если мы говорим о DNS. В DNS только записи. И IP адрес может быть выдан запрашивающему конкретный домен. Понимаешь?
Я могу в регистраторе указать любой ip-адрес, и твой комп, когда ты захочешь обратиться к моему домену, получит именно тот ip адрес, который я указал. Хотя, на этом ip-адресе может вообще не быть железа.
Теперь понимаешь?
ValdikSS, тоже хотел ответить) Не успел.
Вообще, хост подразумевает машину, а вот домен (в контексте DNS) не обязательно имеет машину.
Можно определить IP адрес домена в таблице, под IP адресом может не быть хоста, но доменом он не перестанет быть и "работать")