GaserV: Если вы всё-таки про live-search, то тут одного ангуляра мало. Надо бы поисковик какой-нибудь в backend подключить. Но тут копать достаточно глубоко, чтобы парочкой вопрос-ответ что-то объяснить.
Петр: "The purpose of a filter is to extract the content and properties of files for inclusion in the full-text index" - ok, а на экран он как должен попасть? Я не очень понял ход мысли. Вы предлагаете вывести информацию в контекстное меню файла или в списке закладки "подробно"? Или через контекстное меню файла запускать другую программу, которая будет читать свойства dll и показывать нужные мне свойства в отдельном диалоге? Просто в последнем варианте не нужно делать IFilter, а просто другую программу, которая парсит содержимое файла, на которое его натравили. В этом случае "волшебную" строку можно записать в ресурсы самого файла и не париться атрибутами, а читать ресурс.
Виктор Бузин: Это я знаю, но странно, что в самом Sharepoint встроенного такого механизма нет. Как раз именно этого мы и старались избежать. Пока прикрыли ntlm дополнительным одноразовым кодом для внешней сети, но совсем от ntlm пока не отказаться.
Виктор Бузин: Я не в курсе вашей конфигурации, но по мне так ADFS у вас лишнее звено. Что оно вам даёт? (риторический вопрос). Всё равно у вас осталось NTLM для аутентификации. Суть то в том и была, чтобы аутентифицировать одного и того же пользователя разными методами, т.е. для локальной сети - NTLM, а для внешней - FBA, но права выдавать только один раз.
Проблема в том, что если уже настроены права, то нельзя переопределять провайдера аутентификации. И если изначально настроить пользователей в SharePoint через ntlm, то позже уже нельзя подключить ADFS и аутентифицировать пользователей через неё. Надо будет заново раздавать права, а именно это в моей задаче является невыполнимым. Поэтому ни зону ни провайдера я сменить не могу. Без смены провайдера нет решения?
В данный момент я решил задачу расширения аутентификации средствами IIS, под которым работает Sharepoint.
"процент скопипащеных решений будет уменьшаться" - мне кажется, что со временем процент скопипащенных решений должен только увеличиваться, т.к. понимать написанный код всё-таки быстрее, чем писать свой, нужно только найти его. Но это только со временем.
Петр: Пётр, спасибо. Получилось сделать прототип httpHandler. Информации ооочень мало, примеры все для старого IIS. Самый приличный для IIS 7/8 нашёлся такой: professorweb.ru/my/ASP_NET/base/level4/4_7.php с понятным описанием настроек.
Петр:
Мне нужен фильтр для сайта IIS 8 (на windows 2012 R2 но на D2) ), так что Net очень подходит. Фильтр будет "активироваться" если будет выставлен определённая кука после аутентификации и добавлять ещё одну куку с дополнительной проверкой (там своя кухня в бизнес-логике) и пока вторая кука выставлена, то фильтр работает прозрачно.
Я уже наталкивался на эти классы, но не понял - это тоже самое, что обрабатывать запросы? Просто в IIS обработчики регистрируются на определённые расширения в запросах (как обработчики PHP, например). Я мог бы прописать в качестве расширения "*" или другой wildcard, но правильно ли это?
Вот нашёл один пример: www.codeguru.com/csharp/.net/net_asp/article.php/c... Похож на решение?
И я правильно понимаю, что проект должен генерировать dll?
Виктор Бузин: Спасибо, Виктор, за компонент. Вроде он ничего. Как ни странно, но в другом проекте работа с контролями пошла нормально. Очень странно, если удастся разобраться, то напишу. Генерация при билде меня устраивает.
Спасибо.
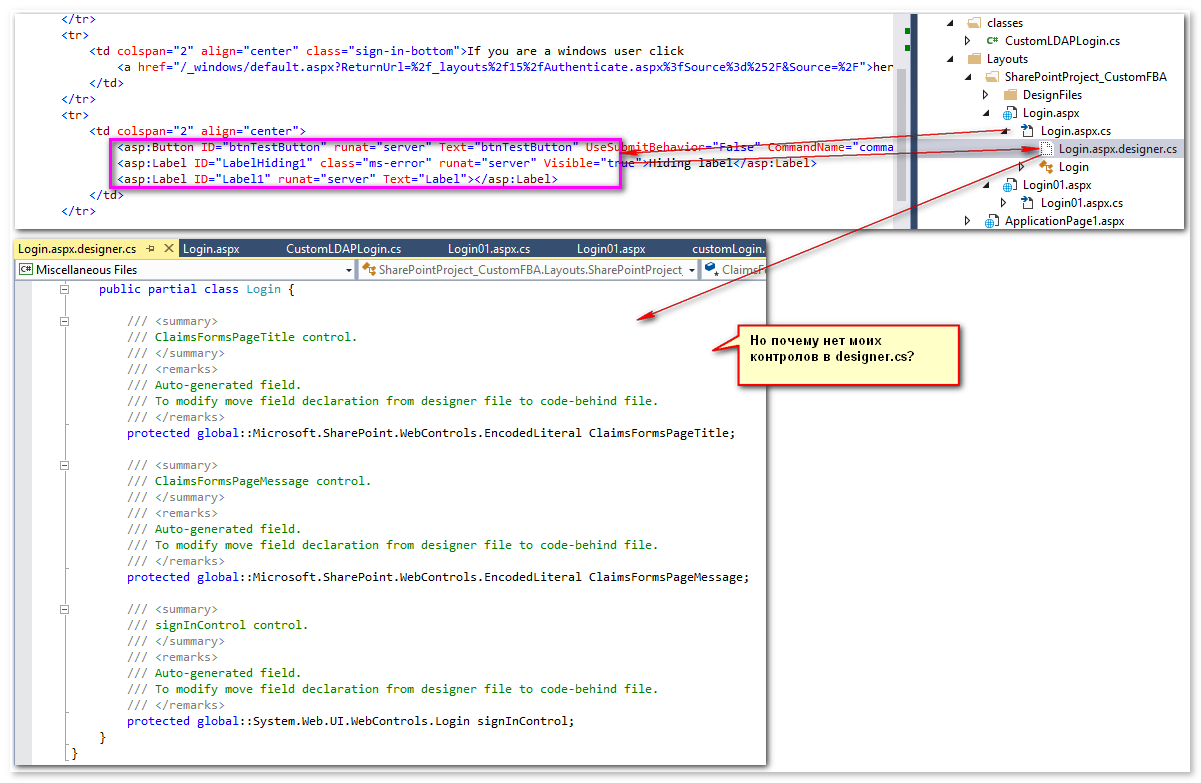
К сожалению, CKSDEV для 2013, у меня 2015. Но меня бы устроило пусть даже без designer, но чтобы мои контролы появлялись в файле *.designer.cs (перегенерируемым автоматически), но ведь не хочет:
Там только несколько штук и мне не понятна такая избирательность - эти asp:контролы беру, а другие нет.
Понимаю, что там всякие предупреждения в *.designer.cs, чтобы не править руками, но экспериментировал - руками добавил свой контрол, так нет - стирает всё-таки. Но почему?
xmoonlight: Непосредственно к php fiddler не цепляется, только к компонентам, которые делают http-запросы и через настройки этих компонентов. Надо искать глобальный способ установки proxy для каждого компонента по отдельности, чтобы не задумываться об обфусцированности кода.
xmoonlight: "Есть некий скрипт который шлет во внешний мир запросы через curl".
О приложении я говорю об этом скрипте. Кто инициатор запуска скрипта? Если пользователь делает запрос, php его обрабатывает и в какой-то момент php требуется внешний ресурс, к которому он получает доступ через http-соединение с помощью curl или file_get_content($link), то такое php-приложение является proxy-сервером. Неважно, что оно дополнительно реализует ещё и бизнеслогику.