скачай
https://www.ozon.ru/context/detail/id/5497130/
есть отсканированная в сети
там ответы на все вопросы
изначально - все как и пишешь
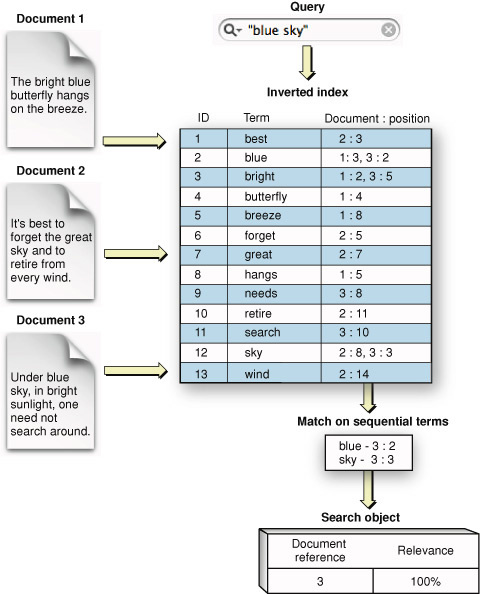
индекс - это список документов в которое входит слова
два слова - два списка
их пересечение - обычный XOR, хз кто сказал что оно ресурсоемко
а вот уже чтобы ответ был РЕЛЕВАНТЕН - там дофига чего наворочено сверху, что
Иван Шумов тебе и пытается объяснить
и да, в современном поиске индекс это список документов соответствующих ВЕКТОРУ запроса
никто его онлайн не делает - все просчитано заранее
онлайн только пытаются свести запрос к наилучшему (нескольким) заренее просчитанным векторам





 Средний
Средний




