Пытаюсь преобразовать все файлы XML в файлы CSV. Для этого использую
python xml_to_csv.py
Сам xml_to_csv.py выглядит следующим образом:
import os
import glob
import pandas as pd
import xml.etree.ElementTree as ET
def xml_to_csv(path):
xml_list = []
for xml_file in glob.glob(path + '/*.xml'):
tree = ET.parse(xml_file)
root = tree.getroot()
for member in root.findall('object'):
value = (root.find('filename').text,
int(root.find('size')[0].text),
int(root.find('size')[1].text),
member[0].text,
int(member[4][0].text),
int(member[4][1].text),
int(member[4][2].text),
int(member[4][3].text)
)
xml_list.append(value)
column_name = ['filename', 'width', 'height', 'class', 'xmin', 'ymin', 'xmax', 'ymax']
xml_df = pd.DataFrame(xml_list, columns=column_name)
return xml_df
def main():
for folder in ['train','test']:
image_path = os.path.join(os.getcwd(), ('images/' + folder))
xml_df = xml_to_csv(image_path)
xml_df.to_csv(('images/' + folder + '_labels.csv'), index=None)
print('Successfully converted xml to csv.')
main()
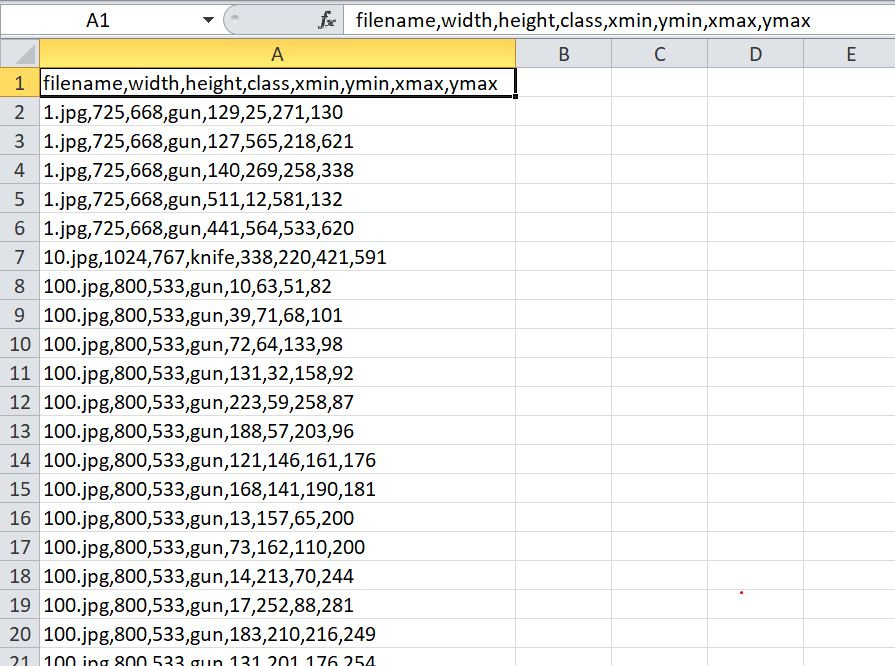
В итоге файлы train_labels и test_labels создаются, но вот заполняется таблица странным образом.Все данные пишутся в один столбец,а хотелось бы что бы каждой переменной была отведена отдельная ячейка.Как это можно сделать?И может ли это как то быть связано с версией Excel?
Что получается сейчас:
1)test_labels
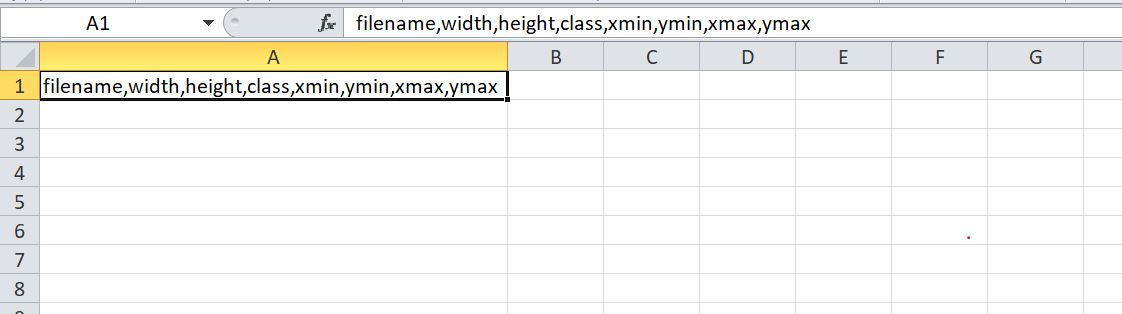
2)train_labels