По поводу обработки текста, вопрос решен. По поводу вставки в excel, думаю проблем ни у кого не будет.
Вот пара ссылок на статьи, которые помогли мне написать регулярку -
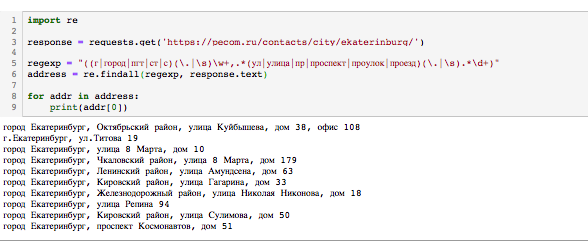
Сама же регулярка, которая у меня получилась выглядит вот так
(г|снт|п)(\.|\,|\s)(\s|\.|.|\D*|\D*\,|\D*.|\D*\s\-|\w*|\W*)(ул|пер|б-р|просп|пр-кт|пр)(\.|\,|\s)(\D*\s|\D*\,|\D*.|\D*\s\-)([\d*\s]{1,3})
Да, я понимаю, что для кого то она покажется убогой, но в моем вопросе, она на 100% справляется :-)
Находит адреса в следующих форматах, например: "г Кемерово ул Проездная 531; г. Москва, ул. Карамшина 222; г, Новокузнецк, ул. 1-ая Стахановская 423; Г. Нижние Патрубки, ул. Оккупация 10;п, Металлплощадка ул, Западная д. 12" и так делее...
p.s. адреса вымышлены