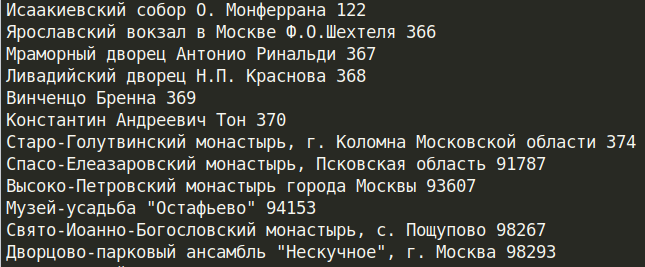
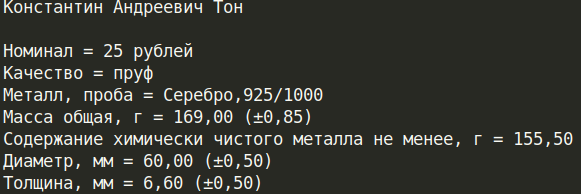
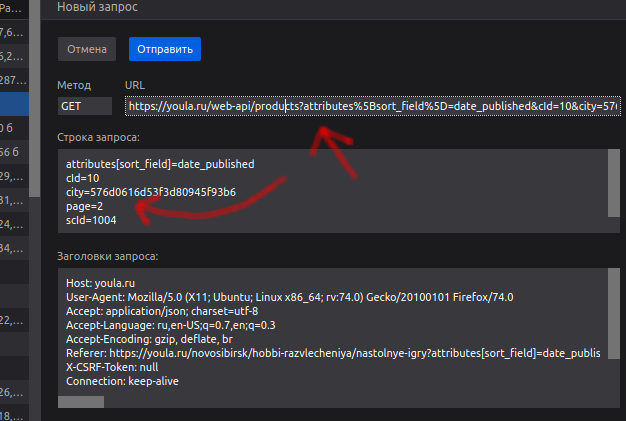
URL_TEMPLATE = "https://youla.ru/novosibirsk/hobbi-razvlecheniya/nastolnye-igry?attributes[sort_field]=date_published"
r = requests.get(URL_TEMPLATE)
return r.text
 Средний
Средний
 Сложный
Сложный