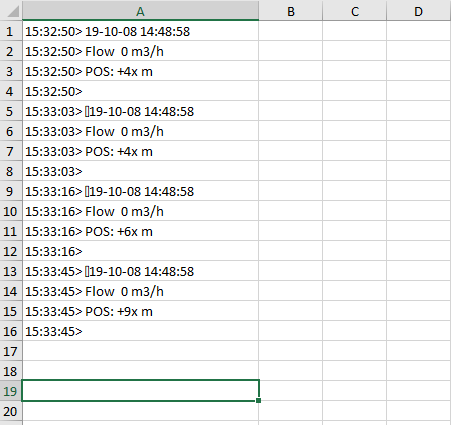
Я бы наверное сгруппировал все данные по дате лога, а потом распарсил значения через regexp (если они фиксированы, можно и жестко по индексу). Примерно так
import openpyxl
import re
wb = openpyxl.load_workbook('name.xlsx')
sheet = wb.active
log = dict()
# перебираем ячейки 1-го столбца и группируем по времени лога
for c in sheet['A']:
key = c.value[:8]
val = c.value[10:]
log[key] = log.get(key,'') + val
rc = re.compile(r"(\d+-\d+-\d+) (\d+:\d+:\d+).*?Flow (\d+).*?POS:.*?(\d+)")
new_data = []
for key, val in log.items():
m = rc.search(val)
if m:
new_data.append(m.groups())
# наши разбитые данные
print('new data:', new_data)
# и записываем результат на новый лист (для простоты через добавление новых строк)
sheet = wb['Sheet2']
for row in new_data:
sheet.append(row)
wb.save('name.xlsx')