from urllib.parse import urlencode, urlparse, parse_qs
from lxml.html import fromstring
from requests import get
import csv
def scrape_run():
with open('/Users/Work/Desktop/searches.txt') as searches:
for search in searches:
userQuery = search
raw = get("https://www.google.com/search?q=" + userQuery).text
page = fromstring(raw)
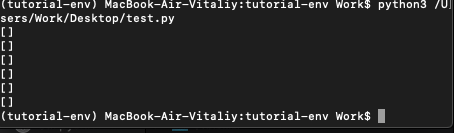
links = page.cssselect('.r a')
csvfile = 'data.csv'
for row in links:
raw_url = row.get('href')
title = row.text_content()
if raw_url.startswith("/url?"):
url = parse_qs(urlparse(raw_url).query)['q']
csvRow = [userQuery, url[0], title]
with open(csvfile, 'a') as data:
writer = csv.writer(data)
writer.writerow(csvRow)
scrape_run()

open('/Users/Work/Desktop/searches.txt')
Простой
Простой
Простой
Средний