import requests
from bs4 import BeautifulSoup as bs
headers = {'accept' : '*/*', 'user-agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.119 Safari/537.36'}
base_url = 'https://www.citilink.ru/catalog/computers_and_notebooks/parts/cpu/?available=1&status=55395790&p=0'
def find_content():
session = requests.session()
request = session.get(base_url, headers=headers)
if request.status_code == 200:
soup = bs(request.content, 'lxml')
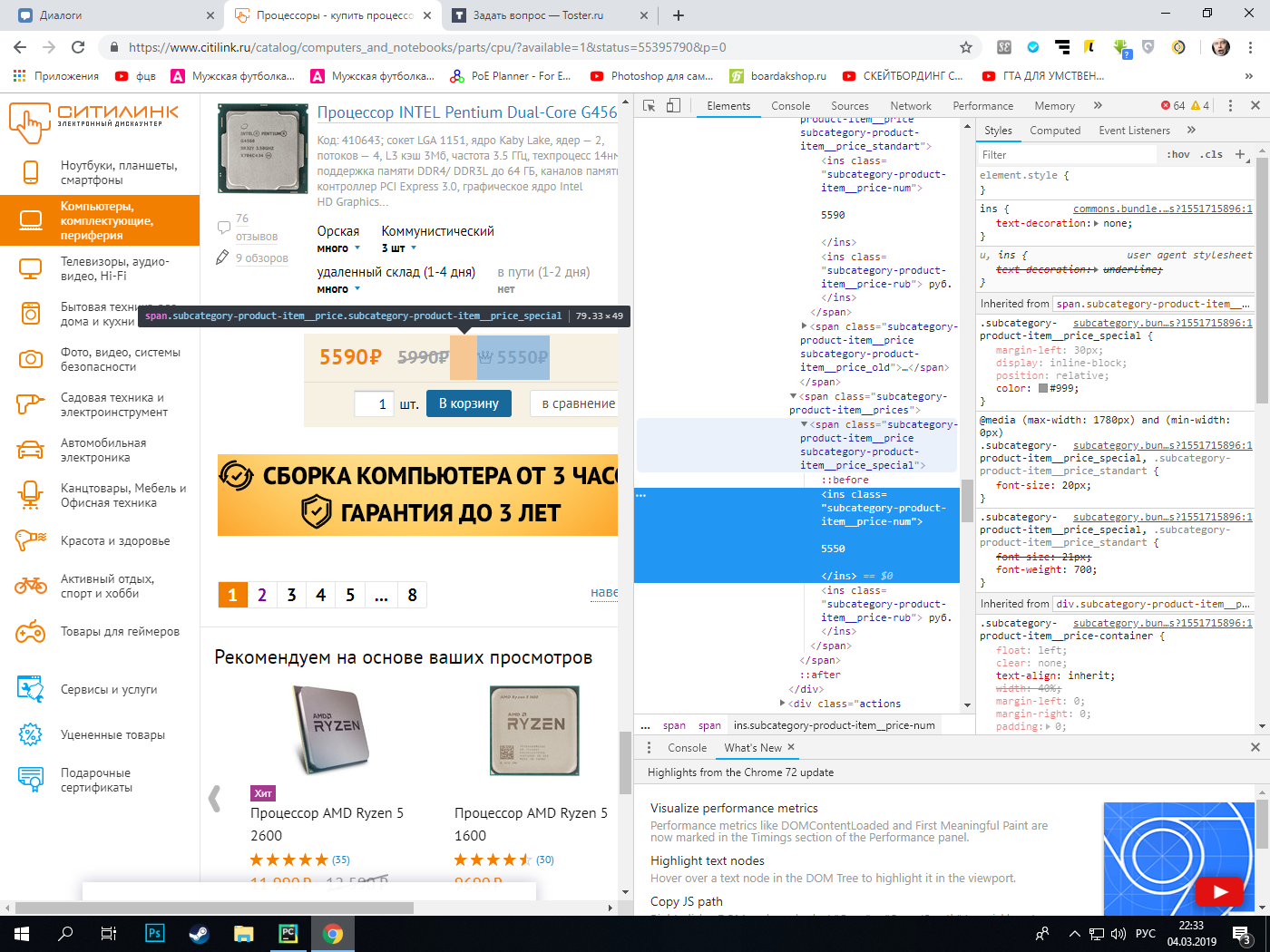
divs = soup.findAll('div', attrs={'class' : 'subcategory-product-item'})
for div in divs:
title = div.find('a', attrs={'class' : 'ddl_product_link'}).text
href = div.find('a', attrs={'class' : 'ddl_product_link'})['href']
about = div.find('p', attrs={'class' : 'short_description'}).text
stand_price = div.find('span', attrs={'class' : 'subcategory-product-item__price_standart'}).text
special_price = div.find('span', attrs={'class' : 'subcategory-product-item__price_special'}).text
print(special_price)
find_content()
Прошу помощи. На сайте, который нужно спарсить есть с классом subcategory-product-item__price_standart и второй span с классом subcategory-product-item__price_special. В этих тэгах хранится тэг ins с одинаковым классом. Так вот, как мне спарсить данные с тэга ins, если выдает ошибку "File Path, line 19, in find_content
special_price = div.find('span', attrs={'class' : 'subcategory-product-item__price_special'}).text
AttributeError: 'NoneType' object has no attribute 'text'
Если ввести тэг ins, то спец. цена будет равна стандартной.