Добрый день!
40 дней назад взял сервер на с процессором Ryzen и дисками 2x500 SSD (
sda+sdb) + 1x4TB HDD (
sdc), сервер зависал раз в 12 часов. После переписки с суппортом выяснилось что проблема в HDD и диск заменили на новый (как они сказали).
Прошло 40 дней, на сервере появилась небольшая нагрузка, и вот уже 2ой день подряд вебсервер перестает работать после того как HDD на котором лежат файлы сайта (базы, и сама система - на SSD). Все это совпало с почти минимальной нагрузкой, до этого ее не было почти совсем
Вдобавок ко всему, при попытке записать файл кэша на диск Апач создает до 100 процессов которые подвисают, и как результат вебсервер вообще перестает работать на обработку запросов, процессы апача просто висят. Решил временно перезагрузкой раз в 5 минут апача.



Вчера я сделал fsck -f -y /dev/sdc
Проверка прошла довольно быстро, после чего перезагрузил сервер полностью и диск стал опять RW.
Вот данные /var/log/syslog
pastebin.com/PtFjWpzk
Сегодня сделал тоже, проверка шла дольше и ошибок больше, решил запустить SMART - жду пока отработает проверка, вот скрин до проверки текущей.
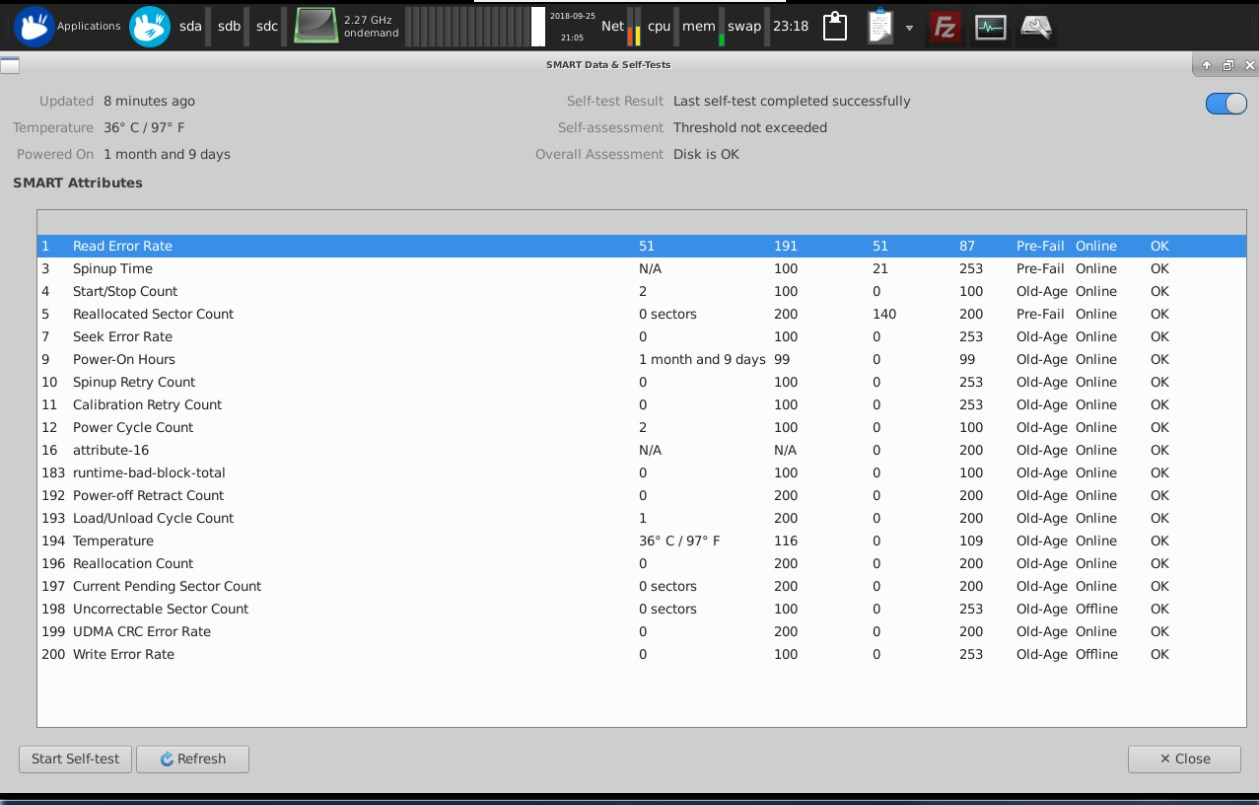
Спустя пол часа работы сервера после перезагрузки уже появилось 96 Bad Sectors, до этого было и 200... :

Контент на диске - 2 ТБ из 4 ТБ , 1ТБ - архивы и дампы , 1 ТБ - файлы по большей части мелкие (файлы кеша html страниц, картинки). Проверял iostat - утилизация была на уровне 5-10%, не больше, это уже когда диск только в Read Only.

Вот как выглядит нагрузка после перезагрузки и диск в RW находится, до того как опять посыпались ошибки.

Вопросы:
1. Отчего может уходить диск в Read-only и связано ли это с нагрузкой?
2. Может ли за месяц придти диск в негодность и какие "вредные советы" для этого?
3. Что делать дальше?
Лог syslog / dmesg pastebin.com/PtFjWpzk
Лог fsck pastebin.com/eSqeuFJc







