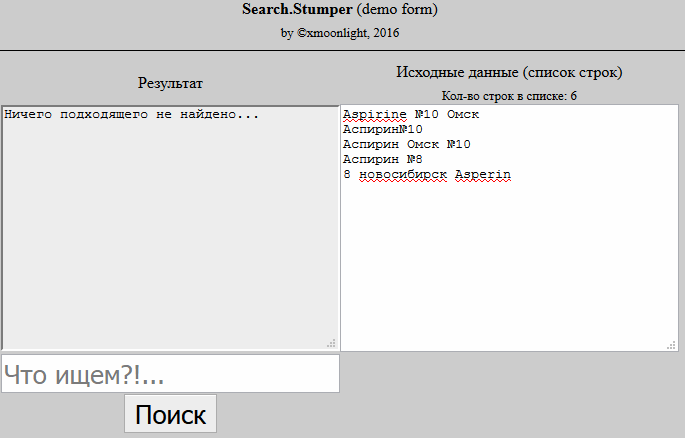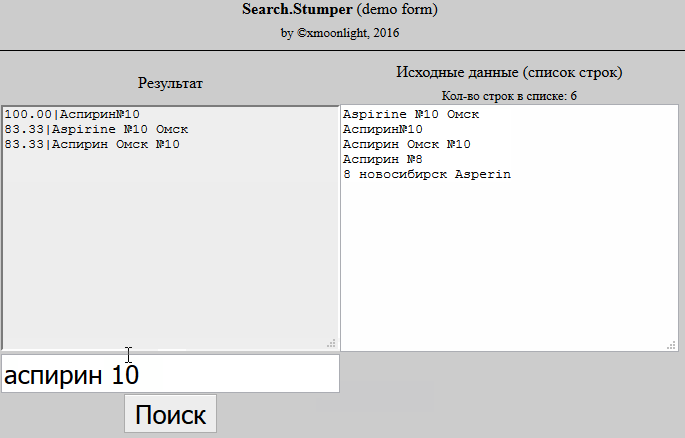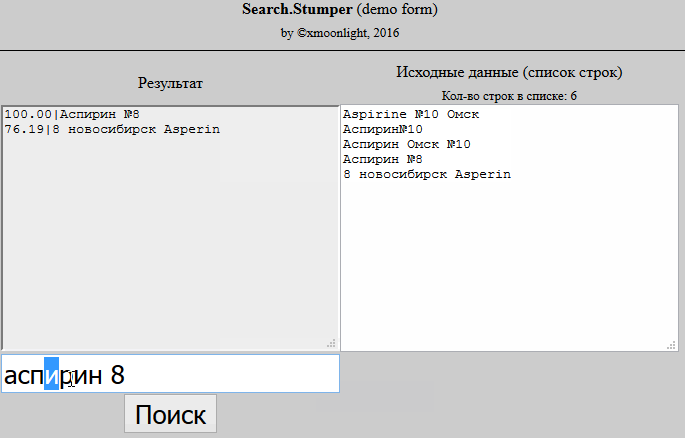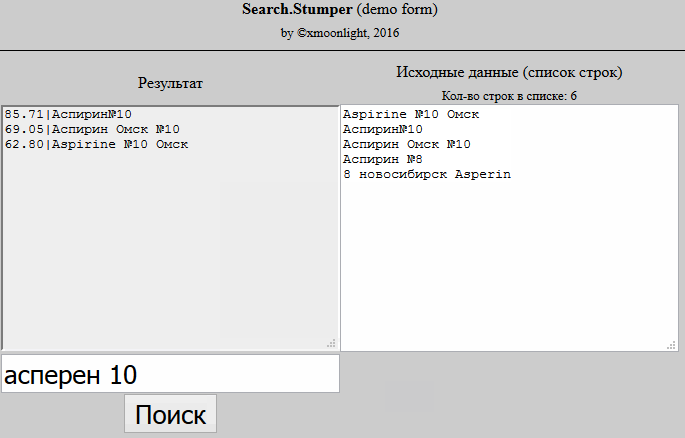
Это тема называется "нечёткий поиск" или "толерантный к ошибкам поиск"или как сказали раннее Fuzzy Search.
Здесь два аспекта: чем искать (технология) и как именно искать (подход, методика).
1) Если у вас мало данных, и они легко помещаются в память то делайте поиск по инвертированному индексу в памяти.
Иначе используйте посковый индекс, напрашивается solr, elasticsearch или чистая lucene .
2) Тюнинг через один из коеффециентов похожести. Я бы посоветовал коэффициент Сёренсена (
https://ru.wikipedia.org/wiki/%D0%9A%D0%BE%D1%8D%D... ) или обратная ему мера Дайса. Расстояние Левенштейна, т.к. это редакционное расстояние решает намного медленее.
Основные шаги:
1) Очистка данных и индексация.
2) Поискоивый запрос и ранжирование по релевантности.





 Простой
Простой