Привет.
Linux, Centos 7 в облаке Yandex. Параметры vm следующие :
Платформа Intel Cascade Lake
Гарантированная доля vCPU 100%
vCPU 2
RAM 8 ГБ
Объём дискового пространства 515 ГБ
Бд размещена на отдельном диске с параметрами:
Размер 465 ГБ
Размер блока 4 КБ
Тип Нереплицируемый SSD
Макс. IOPS (чтение / запись) 75000 / 28000
Макс. bandwidth (чтение / запись) 550 МБ/с / 410 МБ/с
БД - Postgres 11
Функционал - реплика БД, на которую даже не приходят с запросами. Больше vm ничем не занимается.
Конфиг postgres
max_connections = 300
shared_buffers = 4GB
effective_cache_size = 6GB
maintenance_work_mem = 1536MB
checkpoint_completion_target = 0.9
wal_buffers = 16MB
default_statistics_target = 100
random_page_cost = 1.1
effective_io_concurrency = 200
work_mem = 2621kB
min_wal_size = 1GB
max_wal_size = 4GB
max_worker_processes = 8
max_parallel_workers_per_gather = 4
max_parallel_workers = 8
max_parallel_maintenance_workers = 4
checkpoint_timeout = 30min
checkpoint_completion_target = 0.9
autovacuum_vacuum_scale_factor = 0.4
bgwriter_lru_maxpages = 1000
bgwriter_lru_multiplier = 10.0
bgwriter_flush_after = 0
seq_page_cost = 1.0
shared_preload_libraries = 'pg_stat_statements'
ssl = 'on'
ssl_cert_file = '/mnt/keys/server.crt'
ssl_key_file = '/mnt/keys/server.key'
ssl_ciphers = 'HIGH:+3DES:!aNULL'
ssl_prefer_server_ciphers = 'on'
wal_level = 'logical'
wal_keep_segments = 128
log_connections=on
max_standby_streaming_delay = 1800s
max_standby_archive_delay = 1800s
archive_mode = always
archive_command = 'wal-g --config=/mnt/pg-data/.walg.json wal-push \"%p\" >> /var/log/wal-g/wal_g_archive_command.log 2>&1'
Проблема - высокий iowait time на vm. Наш zabbix
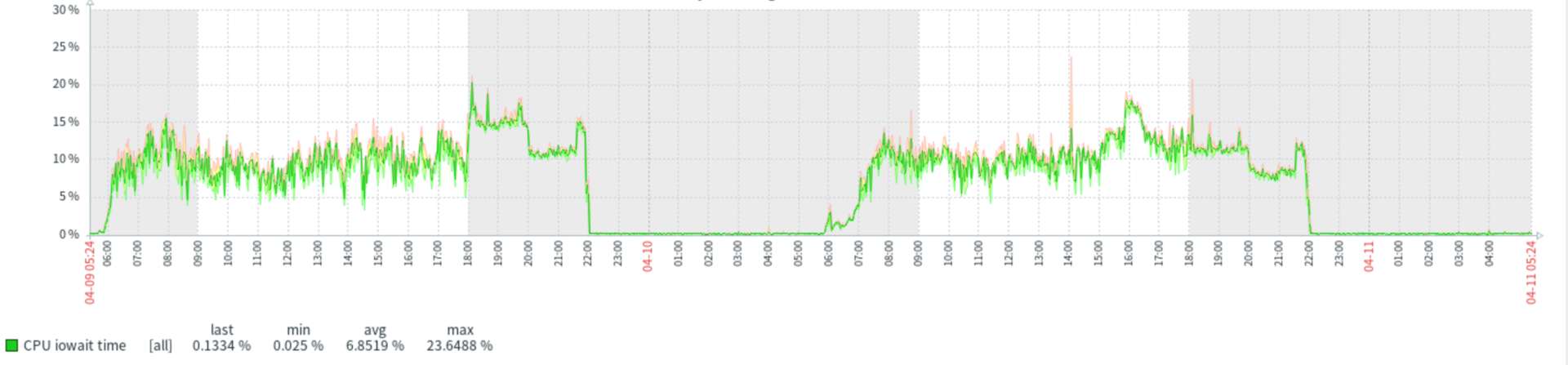
Меня смутило что Latenсy до диска достаточно большой, ответ провайдера
Задержки связаны с работой гостевой ОС и ПО внутри неё, так как графики троттлинга в нуле. По ним можно определить, влияет ли Yandex Cloud на задержки работы дисковой подсистемы. У нас нет возможности еще точнее сказать, в чем может быть причина, так как администрирование ОС и ПО находится в зоне ответственности пользователя и выполняется им самостоятельно.
По iops такой картины не наблюдается, использование диска минимально. Мониторинг диска в облаке -
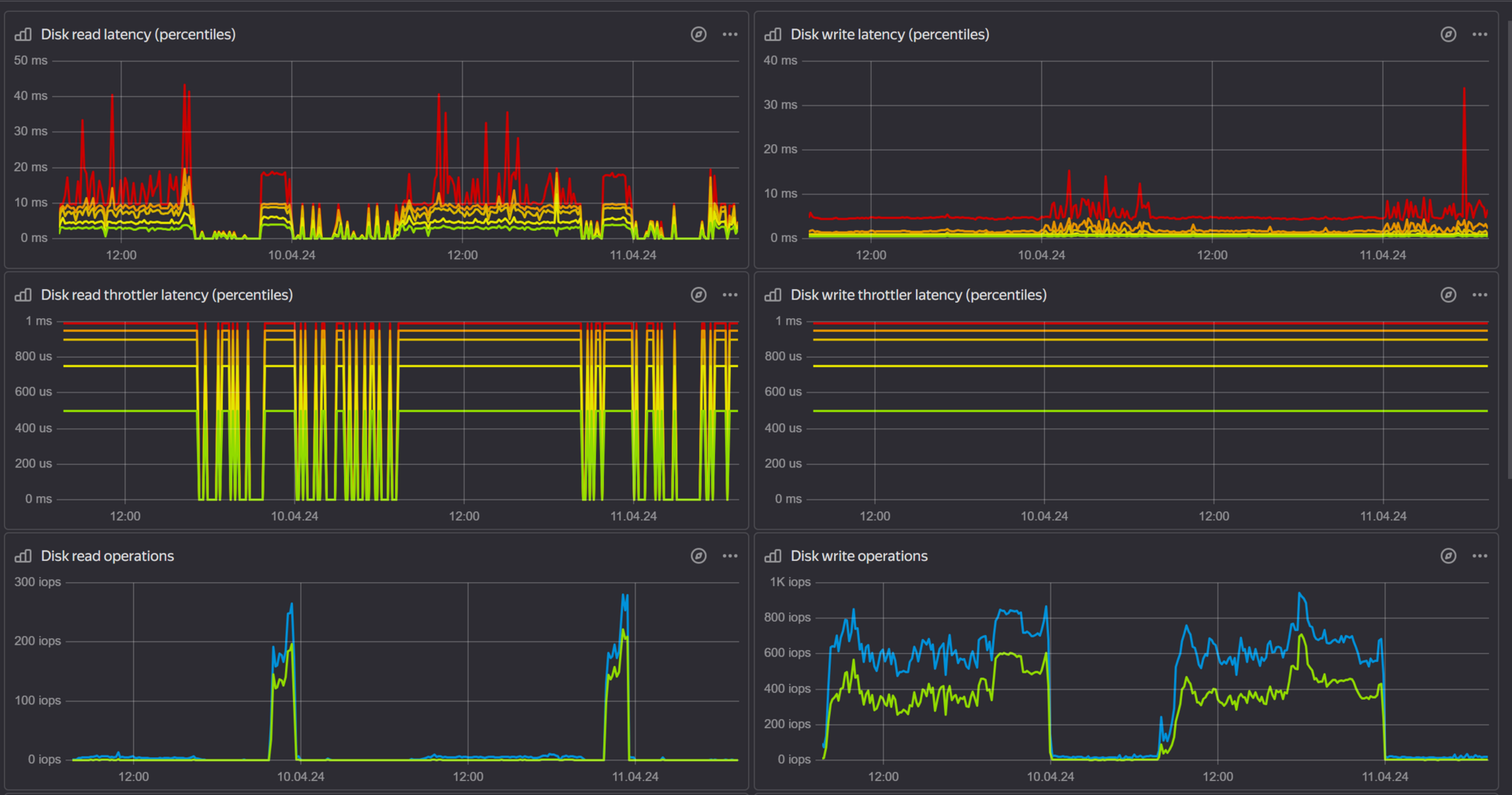
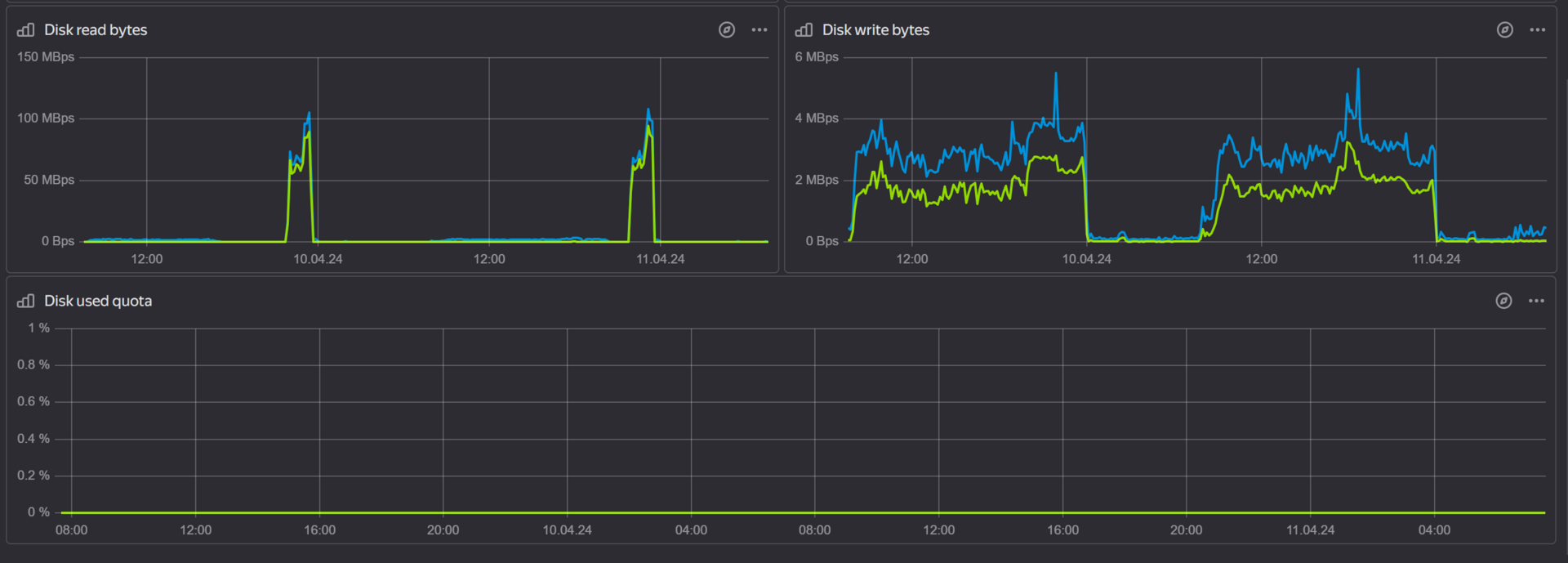
iotop показывает 2-10Мб/c, чтение iostat не помогло, цифры для меня абстрактные и не указывают явно на проблему.
iostat -x 5 5
Linux 5.4.88-200.el7.x86_64 (db-postgres) 04/11/2024 _x86_64_ (2 CPU)
avg-cpu: %user %nice %system %iowait %steal %idle
4.27 0.00 3.74 6.76 1.17 84.07
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
vda 0.00 0.06 0.29 1.46 10.59 7.79 21.02 0.02 10.38 32.67 5.90 1.80 0.31
vdb 0.18 0.79 11.19 264.35 4401.19 1221.74 40.81 0.09 0.71 4.34 0.56 1.15 31.80
avg-cpu: %user %nice %system %iowait %steal %idle
4.66 0.00 5.26 14.58 1.59 73.91
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
vda 0.00 0.60 0.00 2.20 0.00 18.60 16.91 0.01 5.09 0.00 5.09 0.55 0.12
vdb 0.00 0.00 1.00 379.60 30.40 1652.00 8.84 0.14 0.81 0.40 0.81 1.53 58.08
avg-cpu: %user %nice %system %iowait %steal %idle
1.99 0.00 4.27 7.75 1.49 84.49
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
vda 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
vdb 0.00 5.40 0.60 407.60 190.40 1827.20 9.89 0.04 0.48 1.67 0.48 1.14 46.38
avg-cpu: %user %nice %system %iowait %steal %idle
1.99 0.00 4.79 12.46 1.30 79.46
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
vda 0.00 0.00 0.20 0.60 0.80 5.30 15.25 0.01 9.25 1.00 12.00 9.75 0.78
vdb 0.20 0.00 1.40 340.00 444.80 1493.60 11.36 0.14 0.81 2.43 0.81 1.54 52.58
avg-cpu: %user %nice %system %iowait %steal %idle
1.69 0.00 4.47 11.03 1.29 81.51
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
vda 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
vdb 0.00 0.00 0.00 297.20 0.00 1331.20 8.96 0.10 0.78 0.00 0.78 1.59 47.26
Как бы понять природу большого iowait?








