Добрый день!
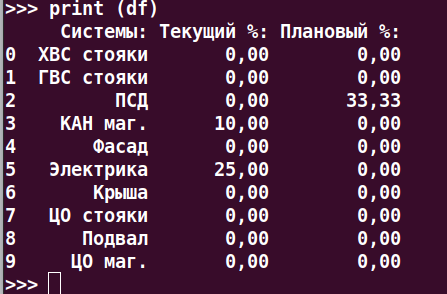
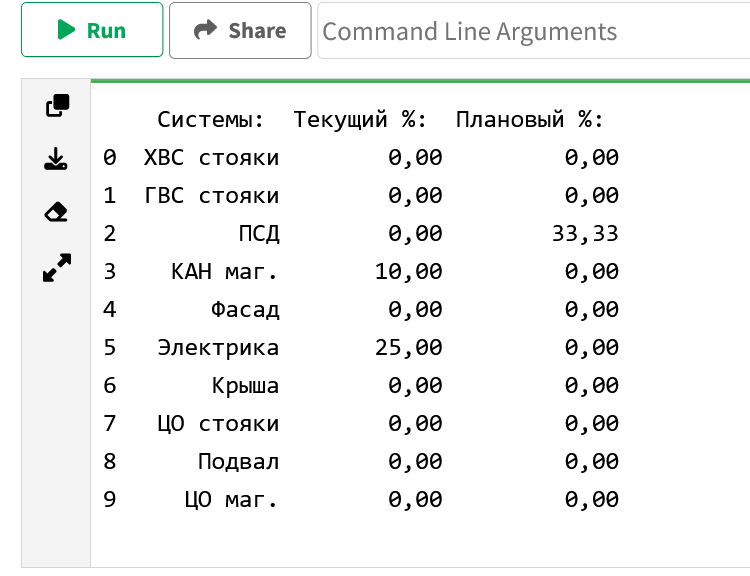
Помогите понять, почему в онлайн интерпретаторе простая таблица - трехколонка выглядит так:
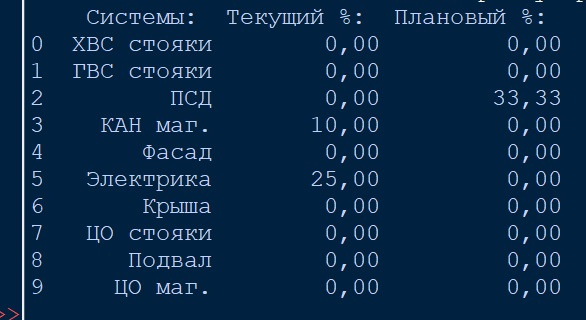
 А в родном IDLE питона выглядит вот так:
А в родном IDLE питона выглядит вот так:
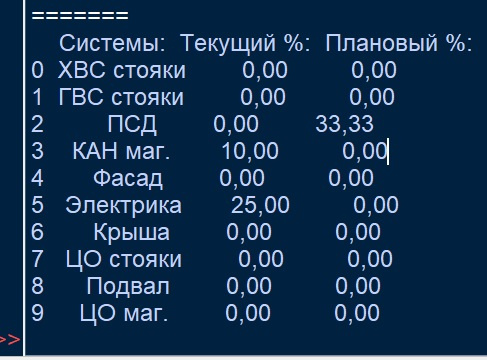
Дело в том, что эта эта инфа улетает из IDLE в бота такая же "кривая", как на второй картинке. У меня от этого агрессия какая-то и зубы скрипят.
Табличка сформирована с помощью pandas. Но я попробовал так же модули tabulate, prettytable и texttable. Везде одна и таже шляпа, применение всяких параметров выравнивания результатов тоже не дает.
Извините, если вопрос глупый, занимаюсь всего пару недель.
Сам код неказистый
import pandas as pd
systems = ['ХВС стояки', 'ГВС стояки', 'ПСД', 'КАН маг.',
'Фасад', 'Электрика', 'Крыша', 'ЦО стояки', 'Подвал', 'ЦО маг.']
proc_current = ['0,00', '0,00', '0,00', '10,00', '0,00', '25,00', '0,00', '0,00', '0,00', '0,00']
proc_plan = ['0,00', '0,00', '33,33', '0,00', '0,00', '0,00', '0,00', '0,00', '0,00', '0,00']
df = pd.DataFrame({'Системы:': systems, 'Текущий %:': proc_current, 'Плановый %:': proc_plan})
print (df)
Или например через pretty table с align параметрами:
from prettytable import PrettyTable
PRtable = PrettyTable()
PRtable.add_column ('Системы:', systems)
PRtable.add_column ('Текущий %:', proc_current)
PRtable.add_column ('Плановый %:', proc_plan)
PRtable.align['Текущий %:'] = "c"
PRtable.align['Плановый %:'] = "c"
PRtable.align['Системы:'] = "r"
print (PRtable)
как всё это выровнять люди добрые?