Здравствуйте!
Нормален ли такой износ SSD при таких вводных?
Имеется сервер 4215R x2, 128 Гб ОП, Windows server 2019, raid10 из 4х Intel D3-S4610 480 гб, контроллер LSI MegaRAID SAS 9361-8i.
Занято 565 из 892 Гб.
На нем крутится 2 виртуалки hyper-v: 1. AD и 2. 1С
Виртуалка 1С: Windows server 2019, 1С 8.3.22.2239, PostgreSQL 15.2-1.1C от 1С, 110 Гб ОП, Занято 372 из 449 Гб диска.
4 базы: УАТ 310 Мб; ЖКХ, по сути БП + блок жкх (основная) 74,15 Гб и две копии для тестов, каждая около 70 Гб (работают в них редко и мало человек). Данные из статистики pgAdmin. Основная в *.dt месяц назад было 12 Гб.
В среднем работает 30-40 человек одновременно.
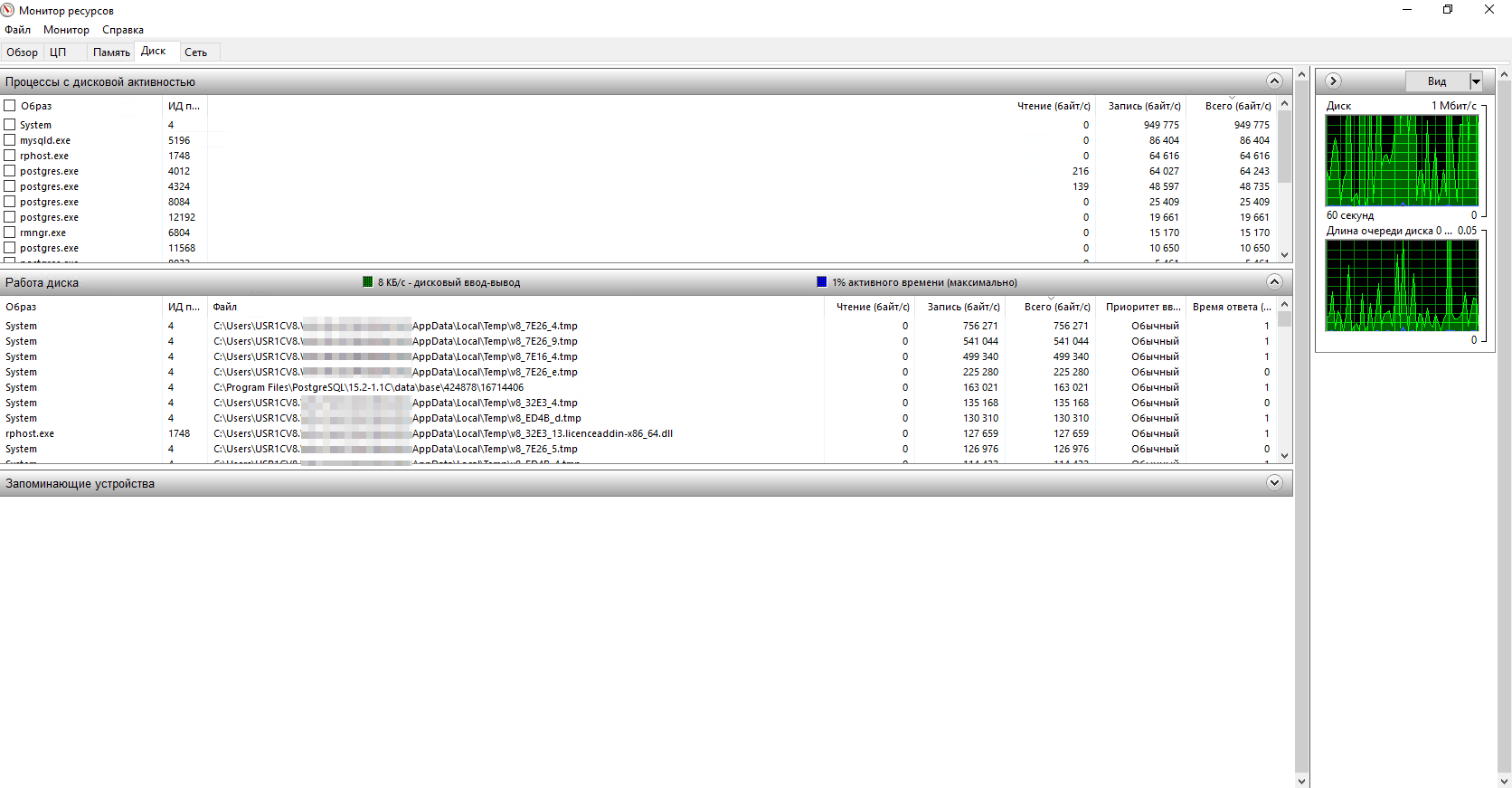
Статистика оставшегося здоровья и записи за сутки из Hard Disk Sentinel:
31.01.24 10:53
26% - 609,47 Тб
82% - 227,87 Тб
32% - 466,92 Тб
87% - 85,76 Тб
01.02.24 12:28
26% - 611,25 Тб, износ 1,78 Тб
81% - 229,66 Тб, износ 1,79 Тб
32% - 467,56 Тб, износ 0,64 Тб
87% - 86,40 Тб, износ 0,64 Тб
Скрин смарта из CrystalDiskInfo под спойлером одного из дисков для примера.
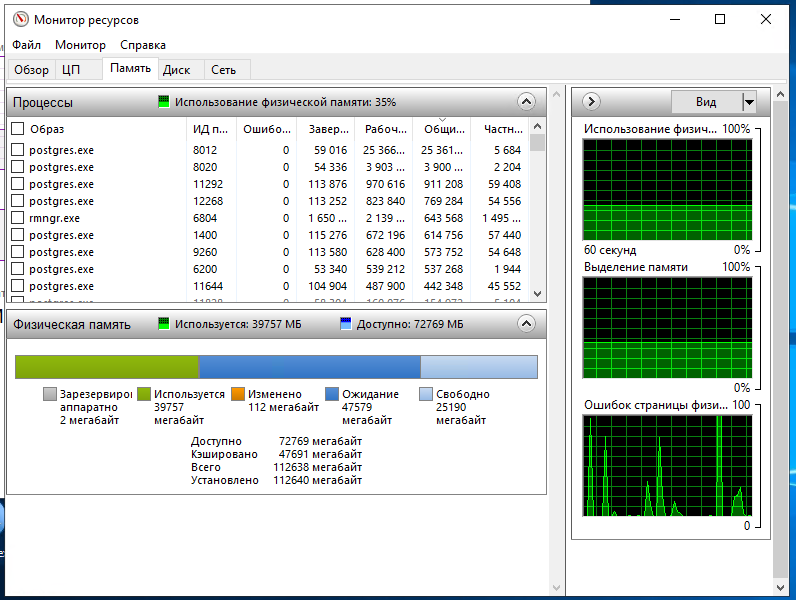
Скрин монитор ресурсов ОП
Может быть такой износ из-за неверно настроенного postgresql'а?
spoilerpostgresql.conf
listen_addresses = '*'
port = порт
max_connections = 500
shared_buffers = 24GB
work_mem = 1024MB
maintenance_work_mem = 2047MB
dynamic_shared_memory_type = windows
max_worker_processes = 28
max_parallel_workers_per_gather = 14
max_parallel_maintenance_workers = 14
max_parallel_workers = 28
wal_buffers = 16MB
checkpoint_completion_target = 0.9
max_wal_size = 16GB
min_wal_size = 4GB
random_page_cost = 1.1
log_destination = 'stderr'
logging_collector = on
log_file_mode = 0640
autovacuum = on
autovacuum_max_workers = 7
autovacuum_naptime = 20s
row_security = off
datestyle = 'iso, dmy'
lc_messages = 'Russian_Russia.1251'
lc_monetary = 'Russian_Russia.1251'
lc_numeric = 'Russian_Russia.1251'
lc_time = 'Russian_Russia.1251'
default_text_search_config = 'pg_catalog.russian'
max_locks_per_transaction = 256
escape_string_warning = off
standard_conforming_strings = off


 Простой
Простой
 Средний
Средний