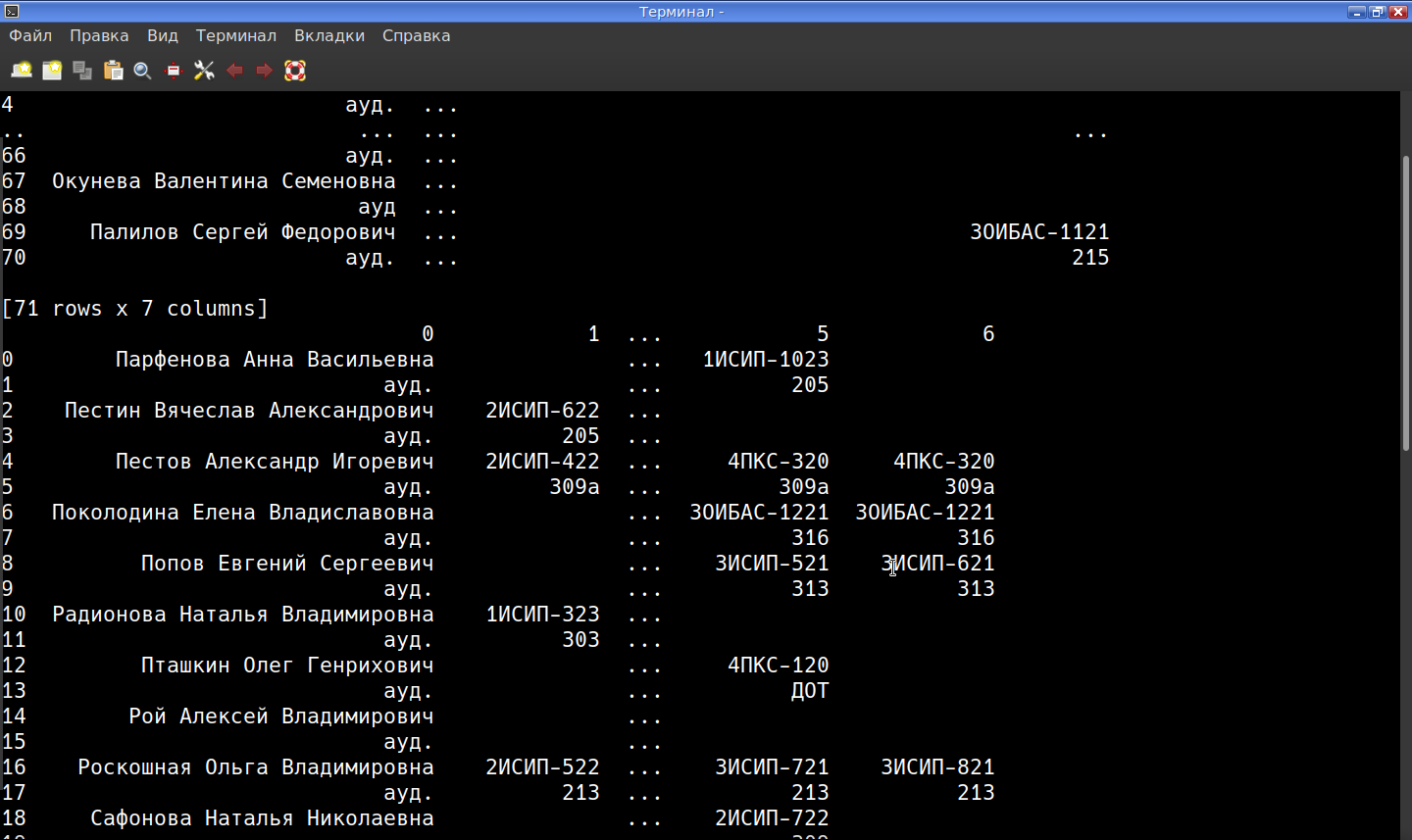
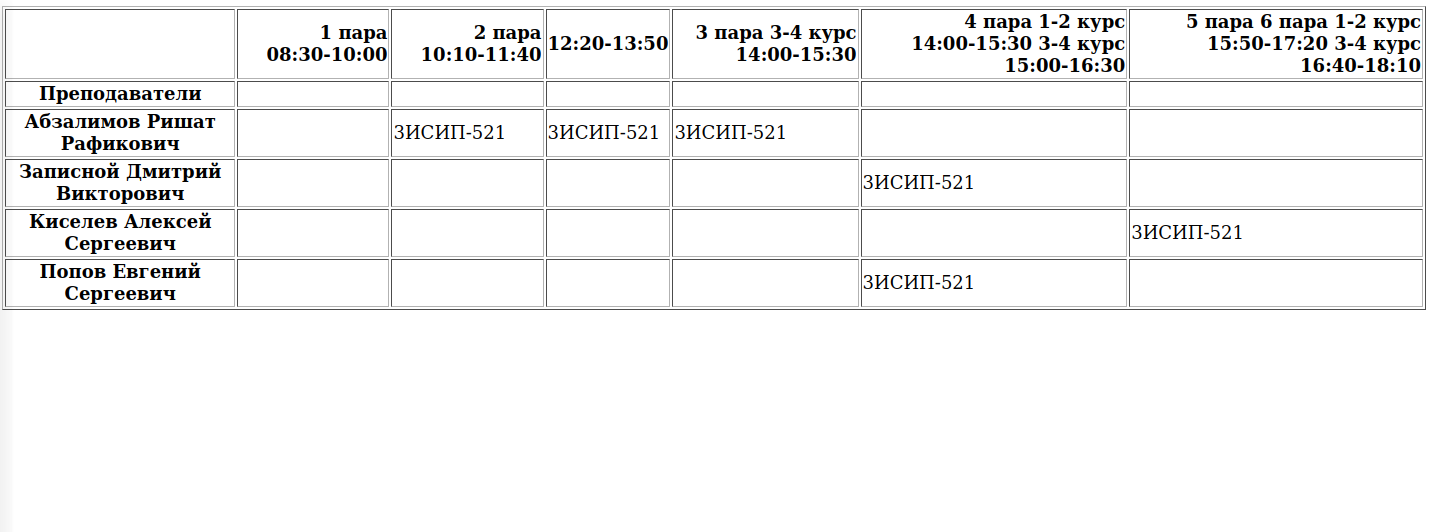
Мне нужно достать допусти для группы 3ИСИП-521 их пары
должно выводить т.к первой пары нет
Найдены следующие данные для группы 3ИСИП-521:
2 пара (10:10-11:40)
102 Абзалимов Ришат Рафикович
3 пара (12:20-13:50)
102 Абзалимов Ришат Рафикович
4 пара (14:00-14:45)
102 кл.час Абзалимов Ришат Рафикович
5 пара (15:00-16:30)
208 Записной Дмитрий Викторович
313 Попов Евгений Сергеевич
6 пара (16:40-18:10)
спорт.зал Киселев Алексей Сергеевич
А у меня выводит без какого либо порядка и без номера пары и времени, как вот сделать чтобы выводило по порядку?
Найдены следующие данные для группы 2ОИБАС-1022:
Ауд. спорт.зал Киселев Алексей Сергеевич
Ауд. 202 Маринич Анна Леонидовна
Вот код
import requests
import io
from telegram.ext import CommandHandler, Updater
from PyPDF2 import PdfReader
import config
def extract_data_from_text(text):
data = []
lines = text.split("\n")
classroom = ""
teacher_full = ""
pair_num = ""
start_index = 0 # Определите переменную start_index здесь
for i, line in enumerate(lines):
if "1 пара:" in line:
pair_num = line.strip() # Запоминаем текущий номер пары
start_index = i + 1 # Устанавливаем значение start_index
if i >= start_index:
if "2ОИБАС-1022" in line:
parts = line.split()
if len(parts) > 3:
teacher_full = " ".join(parts[0:3])
continue
if teacher_full and "ауд." in line:
parts = line.split()
if len(parts) > 1:
classroom = parts[1]
else:
classroom = ""
data.append({'pair_num': pair_num, 'teacher': teacher_full, 'classroom': classroom})
teacher_full = ""
return data
def rasp_command(update, context):
url = 'http://www.fa.ru/org/spo/kip/Documents/raspisanie/%d0%90%d1%83%d0%94%d0%98%d0%a2%d0%9e%d0%a0%d0%98%d0%98.pdf'
response = requests.get(url)
with io.BytesIO(response.content) as open_pdf_file:
reader = PdfReader(open_pdf_file)
num_pages = len(reader.pages)
data = []
for page_number, page in enumerate(reader.pages, start=1):
text = page.extract_text()
extracted_data = extract_data_from_text(text)
if extracted_data:
data.extend(extracted_data)
if data:
# Сортировка данных по номеру пары, если номер пары существует
sorted_data = sorted(data, key=lambda x: int(x['pair_num'].split()[0]) if x['pair_num'] else 0)
message = " Найдены следующие данные для группы 2ОИБАС-1022:"
current_pair_num = None
for entry in sorted_data:
if entry['pair_num'] != current_pair_num:
current_pair_num = entry['pair_num']
message += f"\n{current_pair_num}"
message += f"\n Ауд. {entry['classroom']} {entry['teacher']}"
else:
message = "Данные для группы 2ОИБАС-1022 не найдены"
update.message.reply_text(message)
def main():
updater = Updater(config.token, use_context=True)
dispatcher = updater.dispatcher
dispatcher.add_handler(CommandHandler("rasp", rasp_command))
updater.start_polling()
updater.idle()
if __name__ == '__main__':
main()