Не могу отловить процесс нагружающий Linux процессор?
1. Есть 6 идентичных (но поднятых в разное время) VPS серверов на которых не запущено ничего тяжелого
2. Есть zabbix который показывает редкие мимолетные скачки нагрузки на процессор до 100% на 4 из 6 серверов в разное время
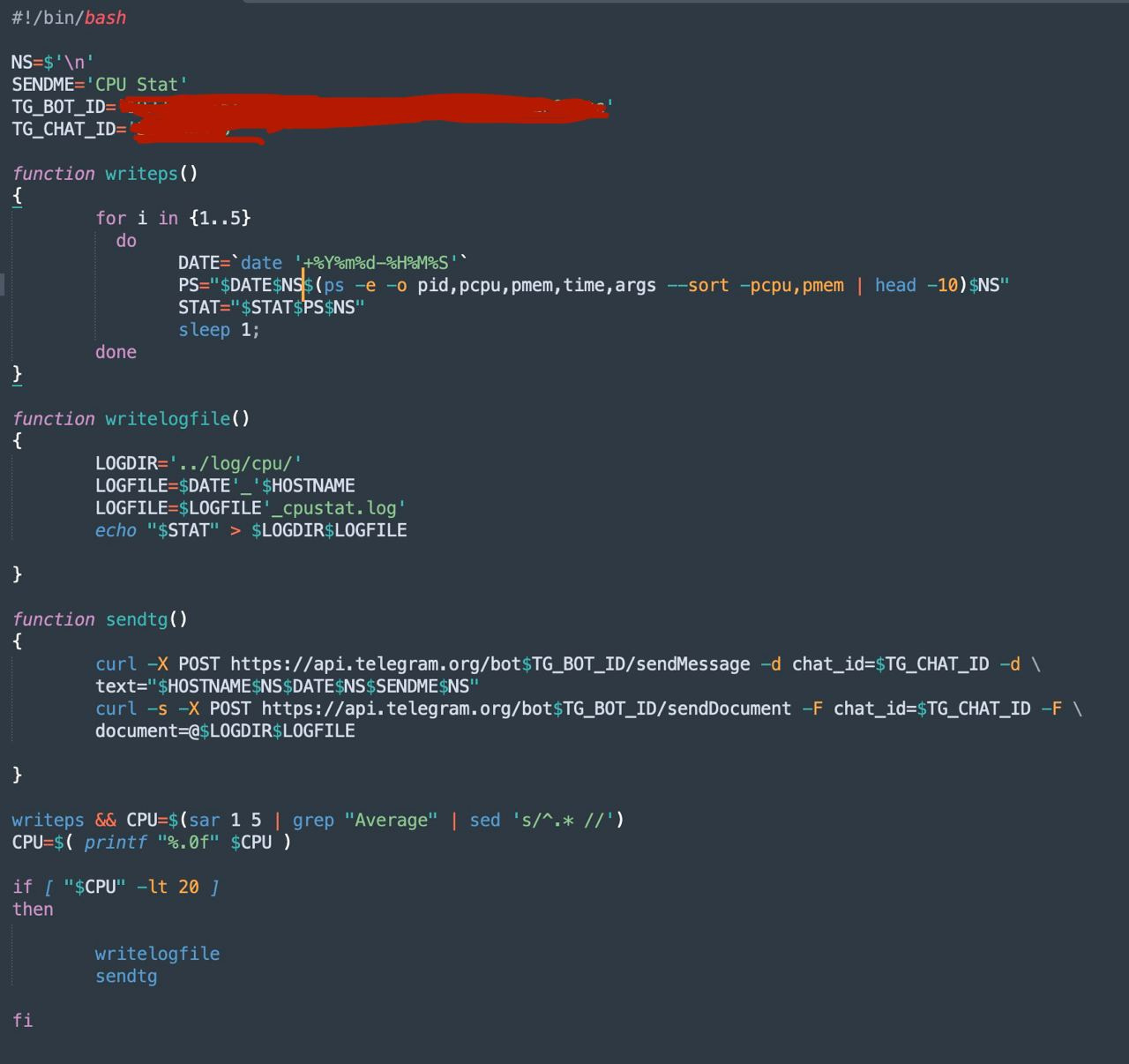
3. Чтоб отловить процесс создающий нагрузку, сделал скрипт, который выполняется кроном каждую минуту и в случае нагрузки процессора более 85% выполнять команду htop, записывать вывод в файл и отправлять в телегу
4. Сделал, настроил, стал ждать, ночью заметил сообщения в телеге с 3 серверов
Но вот незадача, в логе htop не видно процессов с высокой нагрузкой, будто ничего и не было, но zabbix и скрипт то нагрузку заметили...
Не надо ставить как можно больше тэгов. Лучше оставить один, но конкретный, с которым проблема.
См.п.3.1 Регламента. Также обратите внимание на п.3.4, 3.6
все нормально. запускаются какие-либо проги. выполняются процессы.
под капотом ядра куча потоков работает.
любой поток занимает 100% выделенного потока исполнения процессора.
на долю мгновения конечно, что необходимого для проведения своей работы, но забивает поток полностью.
и это тож нормально.
а вот если поток начинает исполнятся длительное (точнее слишком длительное :) ) время, то тут уже надо разбираться.
karabasina, смотри. Существует условно 2 класса систем.
1) Системы реального времени.
2) Джобы.
Это деление условние, и между классами (1) и (2) можно протащить бесконечное число градаций серого цвета.
Если твоя задача которая тебя беспокоит относится к (2) типу - то беспокоиться нечего. Джобу будет плевать
на кратковременные пиковые нагрузки. В той области где я работаю джобы тоже вызывают пики нагрузок
но такова природа bigdata. Короткая высокая нагрузка под 100% в течение 30 минут или часа а потом нет
ничего и кластер можно тушить. Короче говоря - забей.
Если у тебя - система реального времени - то она проектируется по другому. И ее метрики производительности
наблюдаются не по загрузке CPU а условно по чек-поинтами которые пробегает бизнес флоу от стартовой
точки до конечной в системе. В этом случае - ты меряешь не загрузку CPU а пишешь в лог метики.
Например пользователь смотрит котировки запросом и запрос внутри твоей системы работает 1 милисекунду.
Вот эту милисекунду ты и пишешь в лог. Потом в графану и наблюдаешь графики. Потом - разбираешся где
чего. Возможно ты попал на maintenance окно когда твоя VPS делает бекап самой себя. Но стартовой
точкой исследований в твоем вопросе должен быть не пик по CPU а именно реальный отклик твоей системы
в милисекундах. Если отклик хороший (суточная 95 процентиль не превышает 1 мс) то все нормально
и беспокоиться не очем.
В zabbix должна быть возможность посмотреть какого рода нагрузка (system, user и тд). Вполне возможно что это будет steal, такое бывает на VPS, если, например, хост сильно загружен
karabasina, современная ОС - это целый космос. Она иногда живет своей жизнью. Например Windows толи качает и ставит обновление. Толи ntfs чего-то там передвигает. Толи антивирус. Толи IndexingService решил что-то индексировать в МоиДоки. В Linux возможно тоже есть какие-то процессы. Несколько лет назад у меня почему-то RabbitMq брокер сам по себе стартовал и чего-то делал (в старой версии Ubuntu). На нем какой-то функционал был.
Вобщем проведи еще эксперимент. Перенеси свои задачи на соседний VPS и понаблюдай. Будут ли пики.
сделал скрипт, ... в случае нагрузки процессора более 85% выполнять команду htop, записывать вывод в файл...
а не хотите ли нам показать секретную часть скрипта?
xotkot, без проблем
спасибо конечно за картинку(жаль что не аудиофайлом[сарказм]), но разве это то о чем просилось ? там вроде про htop писалось, ну да ладно
дописал щас скрипт, чтоб вывод ps писался несколько раз в переменную одновременно с опросом системы sar, посмотрю как ловить будет
интересная попытка найти секундные всплески используя разные утилиты запускаемые в относительно разное время. Если вам нужна привязка к idle то можно просто взять утилиту top у которой в строке %Cpu(s): в восьмом столбце указанно искомое (id) ну и там же отсортировать по CPU и запустить всё это в пакетном режиме
будет выглядеть примерно так: top -o %CPU -bc -n1
или сразу с обновлялкой в 5 секунд top -o %CPU -bc -d5
ну а дальше уже анализировать результаты
Идете в google, вбиваете performance monitor linux, выбираете подходящую утилиту, например Collectl, настраиваете и ждете всплеска. Потом анализируете полученные данные.
Может лучше написать Bash скрипт который будет средствами системы мониторить все процессы и когда процесс какой то начинает потреблять ресурсы больше чем нужно делать запись о нем в отдельный лог файл?
Можно попробовать atop. Он умеет собирать статистику, и ее потом можно просматривать. Ну, и в интерактивном режиме умеет. Должен быть в стандартных репозиториях.
Единственное надо будет задать интервал сбора метрик покороче, если хочется поймать краткие всплески.
В нагрузке на процессор учитывается нагрузка на диск, при этом в top на процессах вы этой нагрузки не увидите, нужно смотреть параметр wa (это iowait). Также есть утилита iotop. В заббиксе на графике CPU Utilization нагрузка от приложений выделяется синим, нагрузка на диск - жёлтым. Так что если видите жёлтый пик - это диск. В целом такие скачки не являются чем-то из ряда вон выходящим, ОС может свопить, например. Или скрипты сбрасывают результаты работы на диск блоками, при этом диск нагружается. Ещё, если это виртуалка (а это с большой вероятностью виртуалка), на гипервизоре может тормозить диск, тогда и у вас будет тормозить диск, но причину этих тормозов из виртуалки вы не увидите.
Эм, т.е. zabbix у вас есть, но как им мониторить нагрузку вы не понимаете? Так наверное стоит разобраться в заббиксе получше, это ведь и есть система мониторинга! Ну или перейти на более современный prometheus, либо, если серверов немного, то можно заюзать netdata.





 Средний
Средний