Нужно спарсить ссылку на страницу для каждой пары
https://www.lamoda.ru/c/5972/shoes-muzhkedy/?sitel... 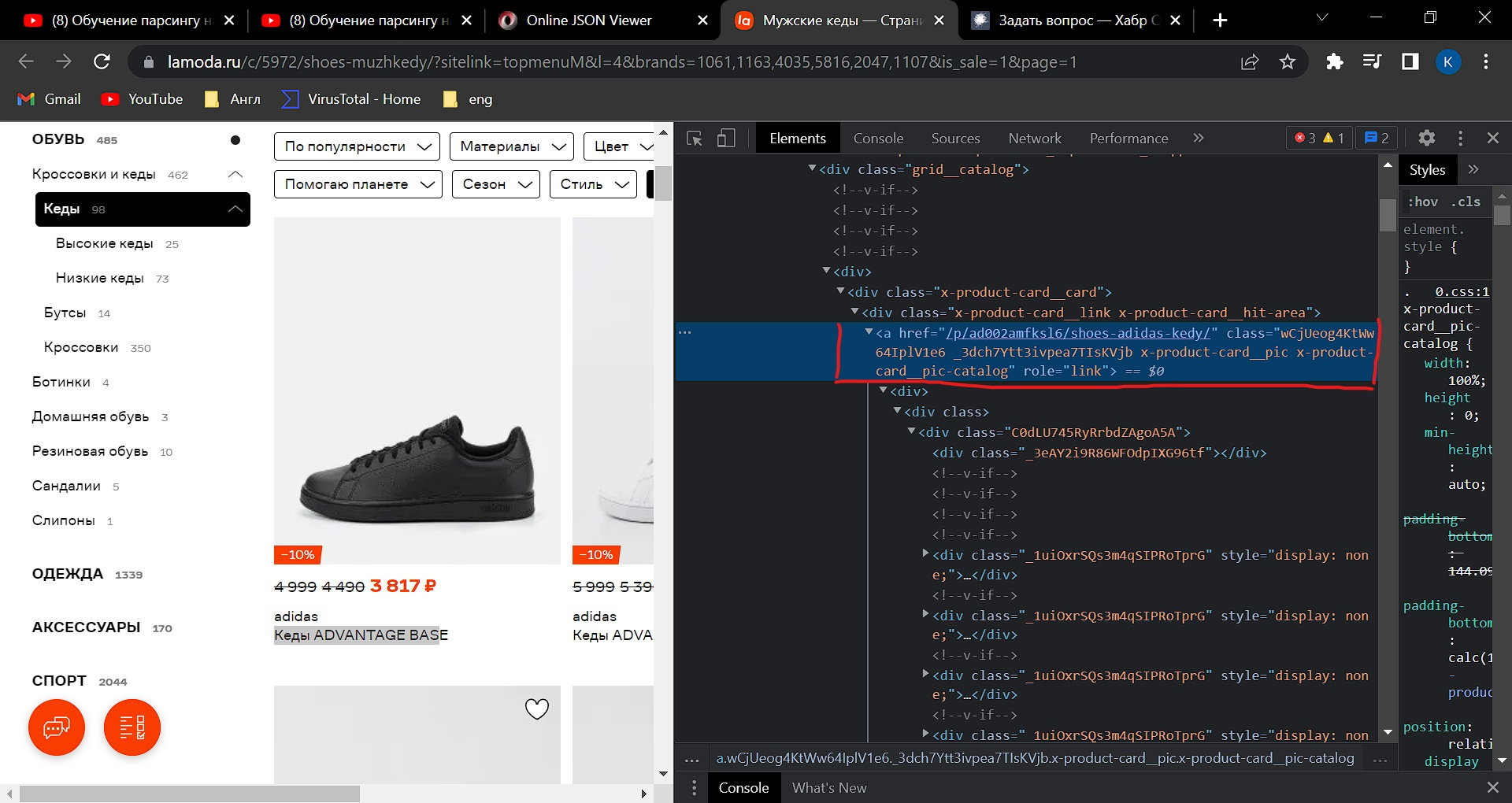
много раз это делал, а тут не получается
import json
import requests
from bs4 import BeautifulSoup
headers ={
"accept": "*/*",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36" ,
}
def get_page(url):
req = requests.get(url,headers = headers)
src =req.text
#print(src)
with open("lamoda2.html", "w") as file:
file.write(src)
soup = BeautifulSoup(src,"lxml")
cards = soup.find("div", class_="x-product-card__card").find("div", class_="x-product-card__link x-product-card__hit-area").find("a",class_=" x-product-card__pic x-product-card__pic-catalog").get("href")
print(cards)
def main():
get_page(url="https://www.lamoda.ru/c/5972/shoes-muzhkedy/?sitelink=topmenuM&l=4&brands=1061,1163,4035,5816,2047,1107&page=1")
if __name__ == "__main__":
main()
ошибка
File "c:/Users/Константин/Downloads/dodit/tgparser.py", line 20, in get_page
cards = soup.find("div", class_="x-product-card__card").find("div", class_="x-product-card__link x-product-card__hit-area").find("a",class_=" x-product-card__pic x-product-card__pic-catalog").get("href")
AttributeError: 'NoneType' object has no attribute 'find'
заранее спасибо




