

dataframe.drop_duplicates(subset=[col1,col2,..],keep=False)cols = ['col1', 'col2', ..]
df.loc[~(df[cols].eq(df[cols].iloc[:, 0], axis=0).all(axis=1))]array = np.array([
['петя', 'ваня', 'ира'],
["катя", 'саша', 'ира'],
['петя', 'миша', 'ира'],
['петя', 'миша','саша'],
])
cond1 = np.any((array == 'петя'), axis=1)
cond2 = np.any((array == 'ира'), axis=1)
comb = cond1 & cond2
array[~comb]удалить строки в многомерном массиве, элементы которого содержат два и более разных значенийэто означит оставить строки только с одинаковыми значениями. изпользуй np.unique()
unique_per_row = np.array([len(np.unique(row)) for row in array])
array[unique_per_row == 1]test_df.columns = ['Shop_1', 'Shop_2', 'Shop_3', 'Shop_4']df = pd.DataFrame({
'A':[1,2,3],
'B':[4,5,6],
'C':[6,7,8]
})
df.columns = ['AA','BB']df = pd.DataFrame({
'A':[1,'a',2],
'B':[1,'a',3]
})
df.loc[df['A'] == df['B']]pd.merge(левая таблица, правая таблица, left_on='CELL',right_on='GeranCellId ', how=method)(
pd.DataFrame({
'string_dates':['17.08.2024','15.08.2024','20.09.2024'],
'values':[10,100,1000]
})
.assign(
dates=lambda x: pd.to_datetime(x['string_dates'],format='%d.%m.%Y')
)
.sort_values(by='dates')
)df = pd.DataFrame({
'userID':[25,188,79],
'goalsID':[[1,2,4,5],[3,6],[1,9]]
})
(
df.loc[lambda x:x['goalsID'].apply(lambda x: 3 in x)]
)print(df[['market_cap'] > 0])print(df[df['market_cap'] > 0])
((x0 - s).abs() <= 3).mean() * 100 Это количество в процентом отношении значений которые отклоняются от x0 в пределах +-3 секунд
(x*q1/q0) это выполняется для каждого значения a2, где x - это каждое значение a2. (синий кейс) Во втором же случае нормальная замена на 95 квантиль любого значения ячейки а2 которое больше 95 квантиля. (красный кейс)
df = pd.DataFrame({
'A':[np.random.randint(1,100,20) for i in range(5)],
})result = (
df.assign(
three_largest = lambda x: x['A'].apply(lambda x: pd.Series(x).nlargest(3).tolist()),
three_largest_index = lambda x: x['A'].apply(lambda x: pd.Series(x).nlargest(3).index.tolist())
)
)result[['one','two','three']] = pd.DataFrame(result['three_largest_index'].tolist(),index=result.index)
resultdf = pd.DataFrame({
'A':[[5,6,24,3],[23,11,15],[3,100]],
'B':np.NaN
})
(
df.assign(
A_max =lambda x: x['A'].apply(max),
B_indexmax =lambda x: x['A'].apply(lambda x: pd.Series(x).idxmax()),
)
)чтобы мне достать из этих столбцов уникальные значенияВот это не совсем понятно, может имелось ввиду из списков, уникальные, и что значит достать.
(
pd.DataFrame({
'ID':[1,2],
'genres':[['Strategy'],['Fightening','Adventure','Arcade']]
})
.explode('genres')
)(
df
.assign(
groups=(df['EventType'] != df['EventType'].shift())
.cumsum()
)
.groupby('groups'
)
.agg(
first= pd.NamedAgg(column='EventTime',aggfunc=lambda x: np.min(x)),
last= pd.NamedAgg(column='EventTime',aggfunc=lambda x: np.max(x)),
EventType= pd.NamedAgg(column='EventType',aggfunc=lambda x: set(x).pop()),
user_id=pd.NamedAgg(column='user_id',aggfunc=lambda x: set(x).pop()),
)
.reset_index(drop=True)
.loc[:,['user_id','EventType','first','last']]
)(
df
.groupby(
(df["EventType"] != df["EventType"].shift())
.cumsum()
)
.agg({"EventTime" : ["min", "max"]})
)(
df.assign(
EventTime=lambda x: pd.to_datetime(x['EventTime'],format='%Y-%m-%d %H:%M:%S')
)
...
)apply он применяется к каждой строке или каждой колонке параметр axis, то есть когда ты пишешь свою кастомную функцию на вход она будет получать либо numpy массив либо pandas Series. Вообще apply для фрейма имеет довольно много интересных параметров почитай доки этого метода он реально мощный. pipe(func, *args, **kwargs) и тебе приходит копия оригинального фрейма с твоими изменениями описанными в func, это очень хорошая практика.
df.loc[:,['A','B','C']] = np.sort(df[['A','B','C']].values,axis=1)result = df.assign(**{
'Системы:':lambda x:x['Системы:'].str.strip(),
'Текущий %:':lambda x:x['Текущий %:'].str.strip(),
'Плановый %:':lambda x:x['Плановый %:'].str.strip()
})
print(result)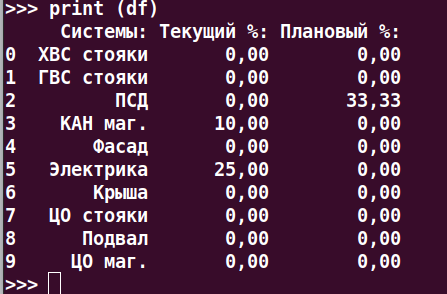
index = pd.date_range('1/1/2000', periods=9, freq='min')
df= pd.DataFrame(data=np.random.randint(1,10,(9,2)), index=index, columns=['A','B'])
df.resample('3min').agg({'A':'sum','B':'mean'})