

from typing import List, Tuple
import csv
SOURCE_CSV = 'source.csv'
SUBSTR = 'ooops'
COL_WITH_VALUES = 1
def main():
data = get_data_from_file(SOURCE_CSV)
filtered_data, clone_rows = data_filter(data, SUBSTR, COL_WITH_VALUES)
save_data(SOURCE_CSV, filtered_data)
def save_data(file_path: str, rows: List[List[str]]):
with open(file_path, 'w', newline='') as f:
w = csv.writer(f)
w.writerows(rows)
def data_filter(rows: List[List[str]], subst: str, col: int) -> Tuple[List[List[str]], List[List[str]]]:
filtered_data = []
clone_rows = []
for row in data:
if row[col] == subst:
rows_with_subst.append(row)
else:
filtered_data.append(row)
return filtered_data, clone_rows
def get_data_from_file(file_path: str) -> List[List[str]]:
with open(SOURCE_CSV, 'r') as f:
data = [x for x in csv.reader(f)]
return data
if __name__ == "__main__":
main()>>> import requests
>>> test = {'elementID': 'find_unp_reestr', 'begin_between': '1', 'end_between': '10', 'unp': '490822627'}
>>> r = requests.post("http://www.portal.nalog.gov.by/ngb/data/", data=test)
>>> r.text
'<tbody><tr><td>490822627</td><td>Общество с ограниченной ответственностью "Джог и Ко"</td><td>23.04.2014</td><td>Абзац 6 п.1.1 Указа 488</td><td/><td/></tr></tbody>'old_dict = {'success': True, 'items': [{'item_id': '556825716', 'market_hash_name': 'Tec-9 | Toxic (Field-Tested)'}, {'item_id': '556646424', 'market_hash_name': 'CZ75-Auto | Tacticat (Minimal Wear)'}, {'item_id': '556646421', 'market_hash_name': 'CZ75-Auto | Tacticat (Minimal Wear)'}]}
# Создаем новый пустой словарь
new_dict = dict()
# Получаем список всех айтемов
items = old_dict['items']
# Обходим все айтемы
for item in items:
# Добавляем нужные значения в новый словарь
# Если данный ключ уже сущесвует, то просто добавляем к списку новый элемент
if item['market_hash_name'] in new_dict:
new_dict[item['market_hash_name']].append(item['item_id'])
# Если нет, то создаем с новым ключем список с одним элементом
else:
new_dict[item['market_hash_name']] = [item['item_id']]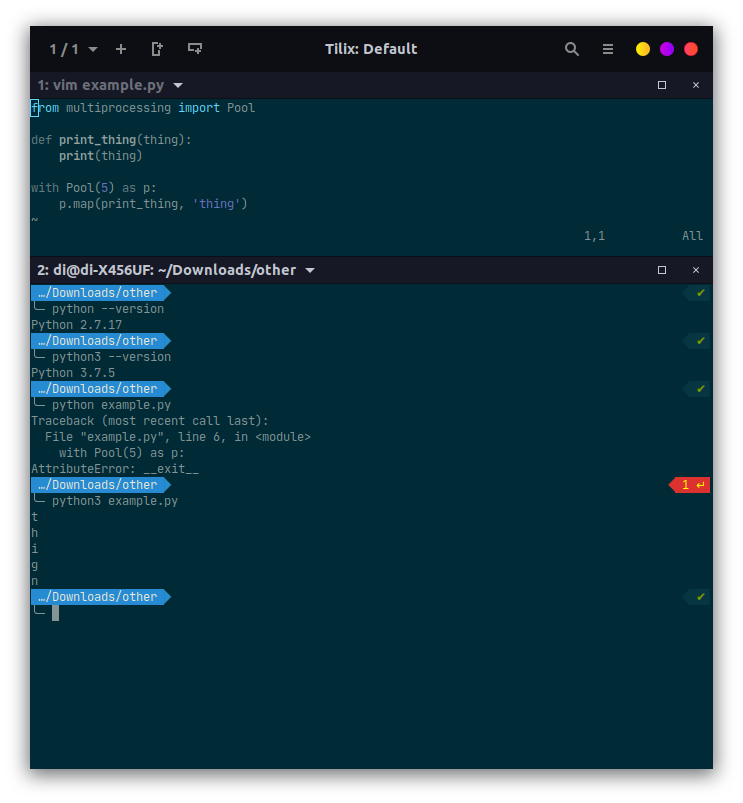
{kind=link}