

function isExistent() {
try {
isExistentValue(value); // эта функция отлавливает отсутствующие данные
} catch (error) {
console.error(error);
// Тут получится отловить ошибку если функция не даст нужный результат
// error - можно использовать тоже как пустую строку или значение по умолчанию
}
}function isExistentValue(tovValue)
{
if (typeof tovValue !== 'undefined') {
// тогда выводим tovValue
}
return ''; // как else только вернёт пустое значение НЕ undefined
}headers: {
'Content-Type': 'application/json',
'Access-Control-Allow-Origin': '*',
'Access-Control-Allow-Methods': 'POST, PUT, DELETE, GET, OPTIONS',
'Access-Control-Request-Method': '*',
},npm cache clean --forcenpm i
process.env
Смарт часы ? Температурные контроллеры ?
Простите, я не понял.
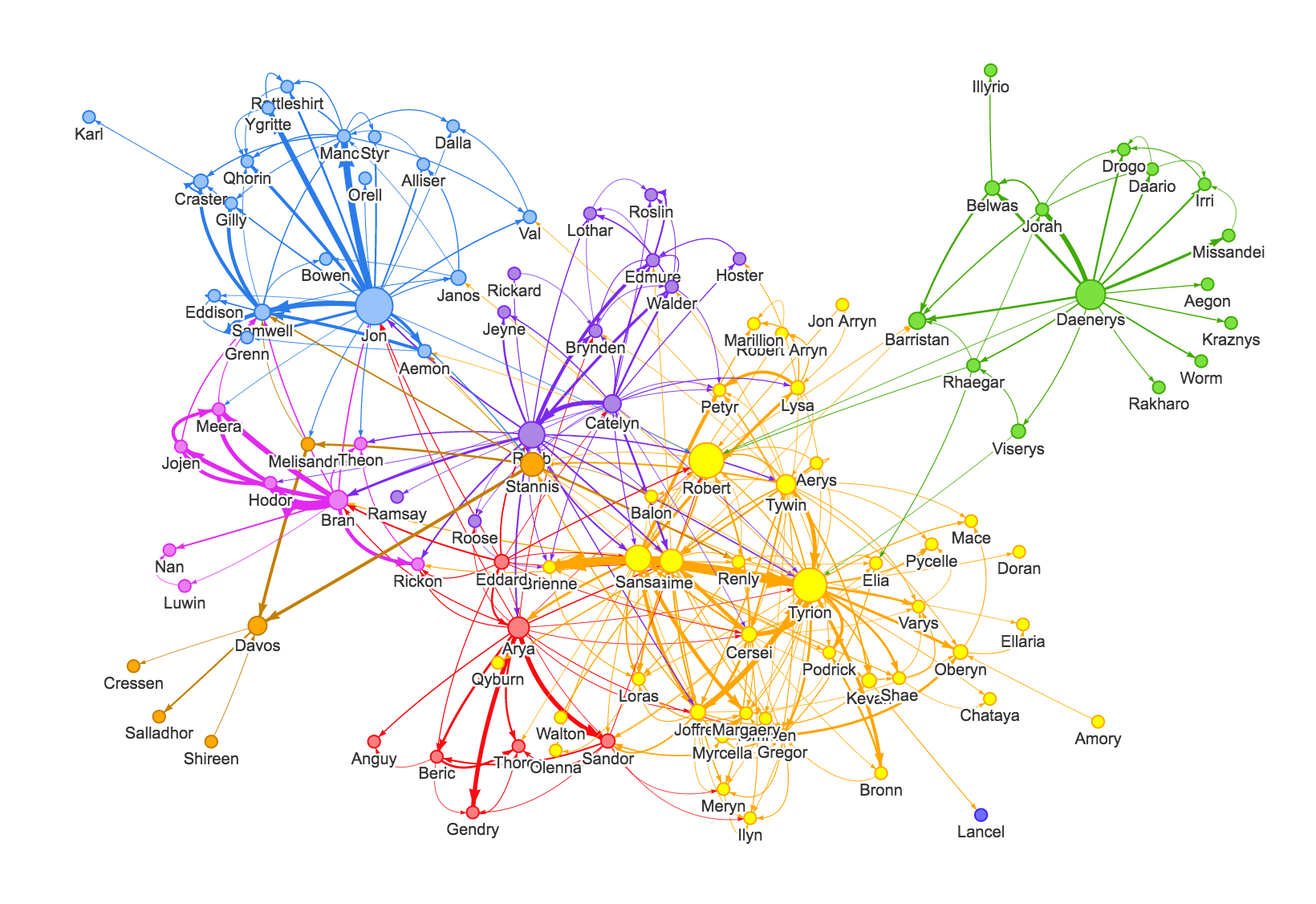
Поясняю ещё раз. Есть условная "википедия", у неё много ссылок и страниц, на некоторых страницах есть такие же ссылки как и на других страницах. Простого парсера ссылок не достаточно, так как это может привести к бесконечной рекурсии. Скрипт при сборе связей будет бесконечно переходить по ссылкам создавая новые связи, но они могут уже быть, как условный скрипт или парсер "поймёт", что он собрал достаточно ссылок и сформировал все связи ?
Понятное дело, что можно сформировать список ссылок первого уровня, остановить скрипт, а потом пройтись по созданному списку, и достать всё ссылки из страниц первого уровня.
Но это алгоритм идеального мира, в реальности, по мимо страниц первого уровня могут быть страницы второго уровня, и третьего и даже четвёртого, и все эти страницы могут ссылаться друг на друга. Вы видели картинку пример, так что можете понимать, на сколько эти связи могут быть сложными. Если считаете что такое реализовать НЕ сложно, опишите алгоритм, который без рекурсии соберёт все уровни страниц, и создаст связи между ними. Я на основании описанного вами алгоритма напишу скрипт и покажу результат его работы.