Вы не правильно поняли - во-первых ingress это сущность кластера kubernetes и к docker отношения не имеет, даже как термин.
Во-вторых - и traefik и nginx и большинство load balancers\reverse proxy умеют проксировать любой tcp трафик, а не только http. Их можно использовать и для smtp трафика в том числе.
думаю, что решение в таком виде, как вы описываете - писать и реализовывать придется самостоятельно, и это превратиться в "кровавую баню".
О боже, как всё сложно...
1) Используйте Resilio File Sync для размазывания файлов по нескольким вашим устройствам.
2) Дополнительно сделайте сервер бэкапа, КОТОРЫЙ САМ будет залезать к вашим данным и выгребать их...
Ну вот, основная нагрузка получается из-за групировке по таблице accounts_audit - full table scan, кстати добавь индексы по одновременно двум полям, указываемых в group by, и само собой по полям, указываемым во where
Так как тебе варианты с готовыми решениями подсказали
SELECT
acc.*
FROM
(
SELECT
accounts.id,
CAST(
CASE
WHEN begin_date_before.parent_id IS NOT NULL THEN begin_date_before.after_value_string
WHEN begin_date_after.parent_id IS NOT NULL THEN begin_date_after.before_value_string
ELSE accounts.monitoring_begin_date
END
AS DATE) AS monitoring_begin_date,
CASE
WHEN name_before.parent_id IS NOT NULL THEN name_before.after_value_string
WHEN name_after.parent_id IS NOT NULL THEN name_after.before_value_string
ELSE accounts.name
END AS name
FROM
accounts
LEFT JOIN
(
SELECT
accounts_audit.parent_id,
accounts_audit.after_value_string
FROM
accounts_audit
INNER JOIN
(
SELECT
parent_id,
field_name,
MAX(date_created) AS last_change
FROM
accounts_audit
WHERE
field_name = 'monitoring_begin_date' AND
date_created < '2022-05-20 00:00:00'
GROUP BY
parent_id,
field_name
) t1
ON
t1.parent_id = accounts_audit.parent_id AND
t1.field_name = accounts_audit.field_name AND
t1.last_change = accounts_audit.date_created
) begin_date_before
ON
begin_date_before.parent_id = accounts.id
LEFT JOIN
(
SELECT
accounts_audit.parent_id,
accounts_audit.before_value_string
FROM
accounts_audit
INNER JOIN
(
SELECT
parent_id,
field_name,
MIN(date_created) AS last_change
FROM
accounts_audit
WHERE
field_name = 'monitoring_begin_date' AND
date_created >= '2022-05-20 00:00:00'
GROUP BY
parent_id,
field_name
) t2
ON
t2.parent_id = accounts_audit.parent_id AND
t2.field_name = accounts_audit.field_name AND
t2.last_change = accounts_audit.date_created
) begin_date_after
ON
begin_date_after.parent_id = accounts.id
LEFT JOIN
(
SELECT
accounts_audit.parent_id,
accounts_audit.after_value_string
FROM
accounts_audit
INNER JOIN
(
SELECT
parent_id,
field_name,
MAX(date_created) AS last_change
FROM
accounts_audit
WHERE
field_name = 'name' AND
date_created < '2022-05-20 00:00:00'
GROUP BY
parent_id,
field_name
) t3
ON
t3.parent_id = accounts_audit.parent_id AND
t3.field_name = accounts_audit.field_name AND
t3.last_change = accounts_audit.date_created
) name_before
ON
name_before.parent_id = accounts.id
LEFT JOIN
(
SELECT
accounts_audit.parent_id,
accounts_audit.before_value_string
FROM
accounts_audit
INNER JOIN
(
SELECT
parent_id,
field_name,
MIN(date_created) AS last_change
FROM
accounts_audit
WHERE
field_name = 'name' AND
date_created >= '2022-05-20 00:00:00'
GROUP BY
parent_id,
field_name
) t4
ON
t4.parent_id = accounts_audit.parent_id AND
t4.field_name = accounts_audit.field_name AND
t4.last_change = accounts_audit.date_created
) name_after
ON
name_after.parent_id = accounts.id
WHERE
accounts.deleted = 0
) acc
WHERE
acc.monitoring_begin_date < '2022-05-20' AND
COALESCE(acc.name) != ''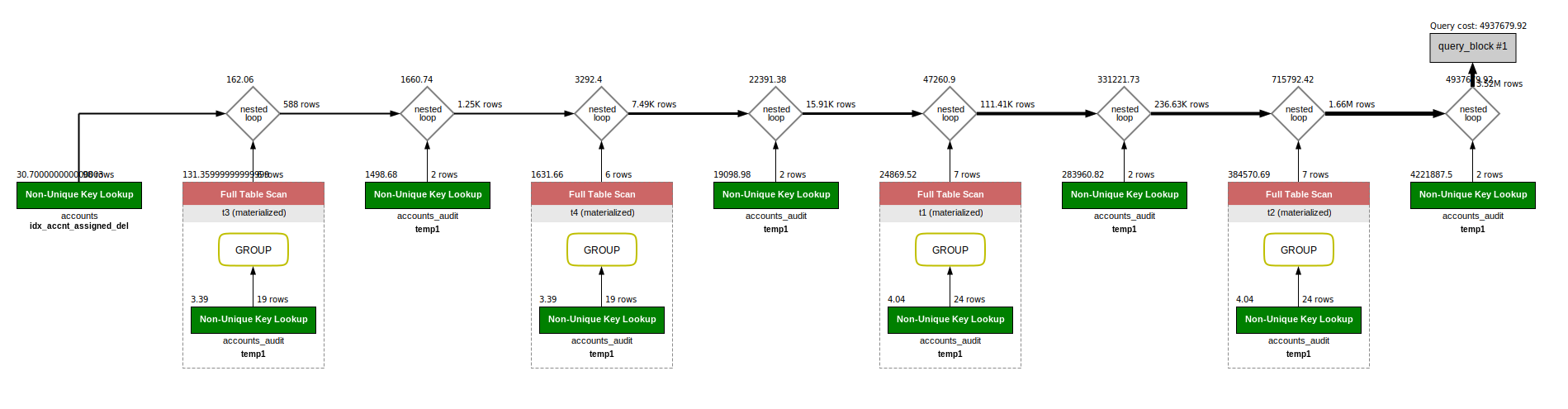
так и надо было писать в вопросе, а не
это не вопрос из серии "стоит ли вообще писать автосты", это вопрос из серии "стоит ли писать тесты ради галочки?". 100% покрытие тестами не гарантирует, что сами тесты покрывают методы полностью.
У меня, почему-то, вообще есть "стойкое чувство", что все связанное со "сборкой" и деплоем должно быть только в конфигурационном файле сборщика gitlab и все... Правда тогда непонятно, как "все это" разворачивать на рабочем месте разработчика и на проде руками.