Как лучше сформулировать sql-запрос для поиска по историческим данным?
Есть две таблицы. Основная (id-GUID, date_create - datetime, value - varchar) и с данными истории/аудита (id - guid, date_created - datetime, parent_id - GUID, before_value - varchar, after_value - varchar). Допустим индексы есть по id и parent_id, но если нужно, то можно добавить любые.
Изначально создается запись в основной таблице. Генерируется случайный GUID, фиксируется текущая дата+время и собственно некоторое значение, включая null. Когда запись в основной таблице изменяется (и только тогда!), в основной таблице просто меняется value плюс создается запись в таблице истории со случайным GUID, текущем датой+временем, parent_id ссылка на id в основной, before_value равно value, которое было, а after_value равно value, которое стало.
Ключевой момент, что запись в таблице с историей создается только если в основной таблице происходит хотя бы одно изменение. Если же запись в основной таблице была создана и никогда не менялось, то в таблице истории о ней данных не будет.
Пример упрощенный, но суть изменить нельзя!
Задача, получить срез значений value из основной таблицы на произвольную дату. Если на отчетную дату запись в основной таблице еще не была создана (date_create больше отчетной даты), то такая запись в результат не включается. Если запись в основной таблице ни разу не изменялась, то вывести текущее значение value. Если были изменения, то из таблицы истории вывести значение, которое действовало на отчетную дату.
В исходной задаче в основной таблице несколько тысяч записей, а в таблице истории несколько миллионов и она постоянно растет. Плюс полей типа value в основной таблице несколько и в результате должно было "историческое значение" для каждого из них...
Я сам уже написал "лобовое решение" для данной задачи, но для одного value оно выполняется от 2 до 10 сек, а для полной выгрузки около 3 минут, что слишком долго...
Можно предлагать создать отдельные view для упрощения. Хранимых процедур желательно избежать, но в крайнем случае можно использовать и их. Сервер MySQL 5.7, БД InnoDB.
У меня в реальности значительно более сложный запрос... Я использую MAX и MIN для поиска наиболее близкого к отчетной дате значения в истории и все это оборачиваю в субзапрос. Плюс сделал дополнительный индекс с датой изменения. Точный explain привести сейчас не смогу...
Вопрос в другом. Как быть в принципе, когда есть история изменений какого-то значения и нужно получить максимально эффективно значение действовавшее на заданную дату?
Может быть предварительно построить какую-нибудь вьюху/витрину, чтобы содержала историю в виде периодов и по ней быстро можно было бы найти нужное значение, т.е. преобразовать имеющиеся структуры к другому виду?
P.S.: Раньше на DBase мне довольно часто приходилось решать подобные задачи. Там обычно использовался индекс с последним элементом в виде даты отсортированной по убыванию и "неточный поиск" ближайшего значения меньше заданного, а потом шел обычный перебор по списку... Возможно в данном случае можно что-то подобное реализовать в виде хранимой процедуры, но не уверен.
HiDiv,
1. Ну вообще для таких вещей есть специализированные вещи типа clickhouse, timescale и тп.
2. Возможно сделать partions - по-моему они в 5.7 есть
3. Есть вероятность что хватит индекса по полю времени
4. Для того что бы судить что из этого лучше explain что бы посмотреть что происходит с запросом
Так как тебе варианты с готовыми решениями подсказали, предлагаю еще вариант - считай промежуточный итог сам, в большинстве случаев всю историю даже хранить не придется, только за последний период, за который накапливаются текущие значения
Большинство функций группировки такие как sum, min, max,.. равны точно такой же функции от этой функции за все промежуточные периоды, грубо говоря считаешь ежемесячный min, сохраняешь их в табличке ежемесячных итогов, а затем чтобы получить за весь период min достаточно брать min от этих сохраненных min значений.
Так как тебе варианты с готовыми решениями подсказали
Со всем уважением к тем, кто откликнулся, я не вижу тут никаких готовых решений!
Первый комментарий относится к window function, но я четко написал, что у меня mysql 5.7, а там их нет... Менять версию СУБД нельзя!
Потом были предложения использовать некие внешние тулзы, но я тоже писал, что могу лишь посылать sql-запрос и добавить пару индексов...
Идея с partions интересна, но не факт, что поможет. Плюс, без очень веских причин не хотелось бы использовать "СУБД-зависимые решения"...
Только индексами похоже проблему не решить...
Судя по всему, абстрактный пример оказался не достаточно информативный, т.ч. привожу "кусок" реального sql-запроса для примера
spoiler
SELECT
acc.*
FROM
(
SELECT
accounts.id,
CAST(
CASE
WHEN begin_date_before.parent_id IS NOT NULL THEN begin_date_before.after_value_string
WHEN begin_date_after.parent_id IS NOT NULL THEN begin_date_after.before_value_string
ELSE accounts.monitoring_begin_date
END
AS DATE) AS monitoring_begin_date,
CASE
WHEN name_before.parent_id IS NOT NULL THEN name_before.after_value_string
WHEN name_after.parent_id IS NOT NULL THEN name_after.before_value_string
ELSE accounts.name
END AS name
FROM
accounts
LEFT JOIN
(
SELECT
accounts_audit.parent_id,
accounts_audit.after_value_string
FROM
accounts_audit
INNER JOIN
(
SELECT
parent_id,
field_name,
MAX(date_created) AS last_change
FROM
accounts_audit
WHERE
field_name = 'monitoring_begin_date' AND
date_created < '2022-05-20 00:00:00'
GROUP BY
parent_id,
field_name
) t1
ON
t1.parent_id = accounts_audit.parent_id AND
t1.field_name = accounts_audit.field_name AND
t1.last_change = accounts_audit.date_created
) begin_date_before
ON
begin_date_before.parent_id = accounts.id
LEFT JOIN
(
SELECT
accounts_audit.parent_id,
accounts_audit.before_value_string
FROM
accounts_audit
INNER JOIN
(
SELECT
parent_id,
field_name,
MIN(date_created) AS last_change
FROM
accounts_audit
WHERE
field_name = 'monitoring_begin_date' AND
date_created >= '2022-05-20 00:00:00'
GROUP BY
parent_id,
field_name
) t2
ON
t2.parent_id = accounts_audit.parent_id AND
t2.field_name = accounts_audit.field_name AND
t2.last_change = accounts_audit.date_created
) begin_date_after
ON
begin_date_after.parent_id = accounts.id
LEFT JOIN
(
SELECT
accounts_audit.parent_id,
accounts_audit.after_value_string
FROM
accounts_audit
INNER JOIN
(
SELECT
parent_id,
field_name,
MAX(date_created) AS last_change
FROM
accounts_audit
WHERE
field_name = 'name' AND
date_created < '2022-05-20 00:00:00'
GROUP BY
parent_id,
field_name
) t3
ON
t3.parent_id = accounts_audit.parent_id AND
t3.field_name = accounts_audit.field_name AND
t3.last_change = accounts_audit.date_created
) name_before
ON
name_before.parent_id = accounts.id
LEFT JOIN
(
SELECT
accounts_audit.parent_id,
accounts_audit.before_value_string
FROM
accounts_audit
INNER JOIN
(
SELECT
parent_id,
field_name,
MIN(date_created) AS last_change
FROM
accounts_audit
WHERE
field_name = 'name' AND
date_created >= '2022-05-20 00:00:00'
GROUP BY
parent_id,
field_name
) t4
ON
t4.parent_id = accounts_audit.parent_id AND
t4.field_name = accounts_audit.field_name AND
t4.last_change = accounts_audit.date_created
) name_after
ON
name_after.parent_id = accounts.id
WHERE
accounts.deleted = 0
) acc
WHERE
acc.monitoring_begin_date < '2022-05-20' AND
COALESCE(acc.name) != ''
Это запрос только по двум полям, а мне нужно получить подобным образом 5, а потом еще join с другой таблицей с подобной же стуктуры.
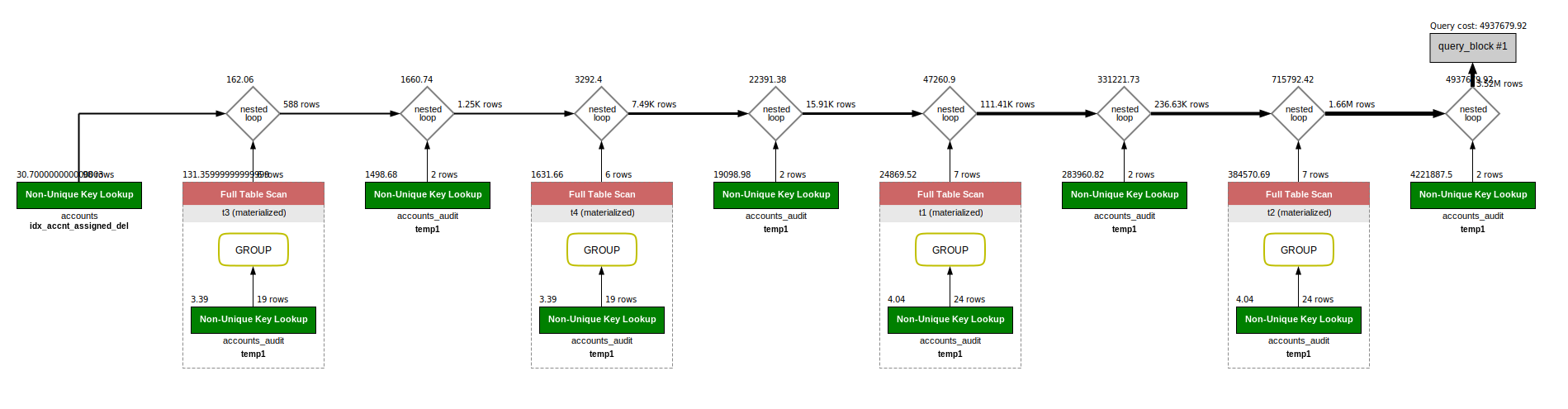
Вот это explain этого запрос на полупустой тестовой базе
Ну вот, основная нагрузка получается из-за групировке по таблице accounts_audit - full table scan, кстати добавь индексы по одновременно двум полям, указываемых в group by, и само собой по полям, указываемым во where
Если индексы будут использоваться но все же будет медленно либо к примеру индексы будут замедлять запись то используй партицирование как я предложил.
Хотя, если в фильтрации у тебя используется плавающая дата (2022-05-20 00:00:00), то предлагаемый мной метод не очень подойдет (точнее подойдет но кодить придется заметно), грубо говоря ты создаешь таблицу accounts_audit_grp, куда складываешь (однократным скриптом по окончанию периода) все 'старые данные' сразу с агрегацией min но в пределах этого интервала, раз в например сутки (если твоя дата фильтрации меняется как раз с шагом в сутки) тогда min будет вычисляться точно таким же запросом, и самое главное, эти старые данные удаляй из изначальной таблицы accounts_audit (ну в архив без индексов перемещай)
данные по текущему интервалу досчитывай по основной таблице
т.е. у тебя будет таблица accounts_audit_grp с полями parent_id,field_name,max_date_created,min__date_created,grp_date где min и max значения в пределах grp_date и grp_date+размер интервала
Ну вот, основная нагрузка получается из-за групировке по таблице accounts_audit - full table scan, кстати добавь индексы по одновременно двум полям, указываемых в group by, и само собой по полям, указываемым во where
Это план уже при наличии всех возможных индексов. Там есть (parent_id, field_name, date_created), (field_name, parent_id, date_created), просто parent_id, просто date_created. Ни один из этих индексов не спасает от full table scan.
Дата в запросе это произвольная дата в прошлом, на которую нужно создать отчет.
В общем я перепробовал кучу решений и пришел к выводу, что создать на лету отчет "по истории" с такими требованиями при такой конфигурации таблиц, просто невозможно.
В качестве решения, завел в БД таблицу, точно повторяющую структуру отчета, и сделал ежедневно запускаемое задание, которые заполняет ее данными за текущий день без всяких таблиц истории и т.п. Получил практически мгновенно работающий отчет, который выдает данные за любую дату, которая уже посчитана в этой таблице...