
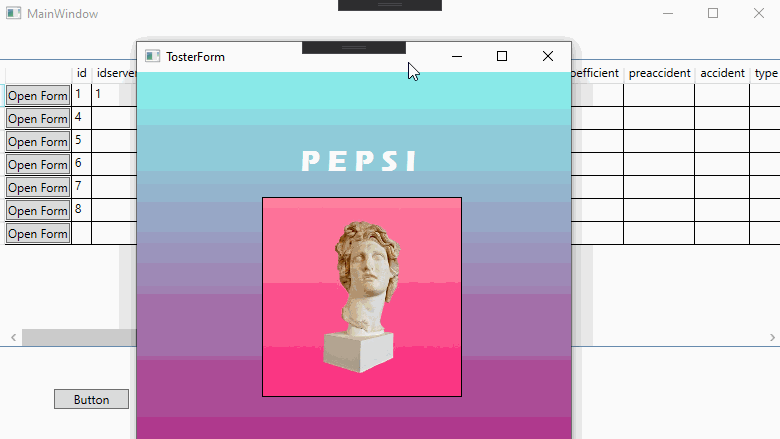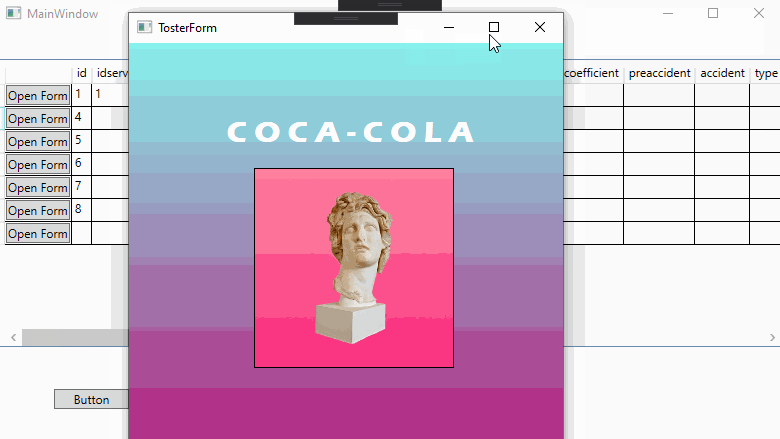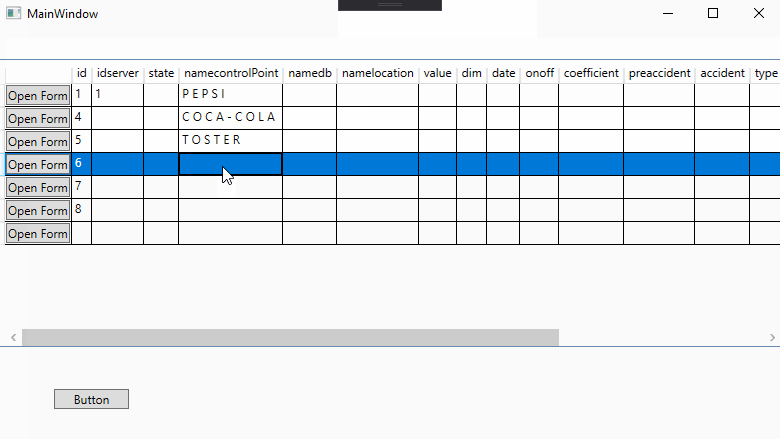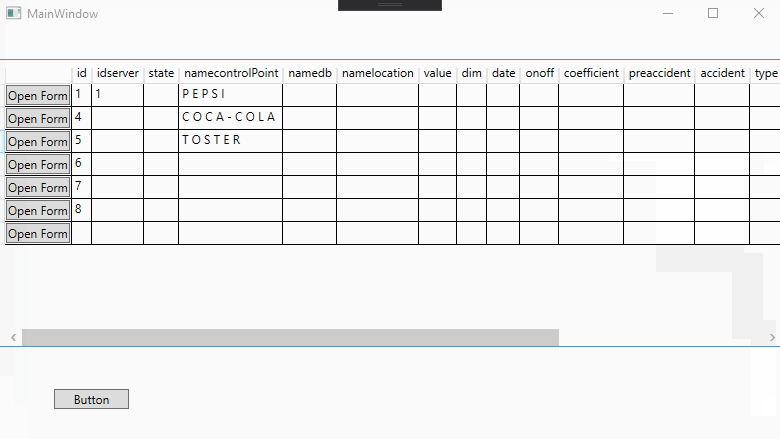
<DataGrid Name="MyDataGrid" ItemsSource="{Binding Table}">
<DataGrid.Columns>
<DataGridTemplateColumn>
<DataGridTemplateColumn.CellTemplate>
<DataTemplate>
<Button Click="Button_Click">Open Form</Button>
</DataTemplate>
</DataGridTemplateColumn.CellTemplate>
</DataGridTemplateColumn>
</DataGrid.Columns>
</DataGrid>private void Button_Click(object sender, RoutedEventArgs e)
{
TosterForm form = new TosterForm(((DataRowView)MyDataGrid.SelectedItem).Row.ItemArray[3].ToString());
form.ShowDialog();
}
DataTable Table{get; set;}
DataAdapter dataAdapter;
private void DeleteMethod(object obj)
{
var indexDataTable= //получаете здесь индекс из колонки "индекс"(например) выбранной строки
var indexDataGridRow = //тут индекс самой строки, чтобы удалить ее из DataTable, либо вообще DataTable заново получать
using (SqlCommand cmd = new SqlCommand())
{
cmd.Connection = new SqlConnection(connectionString);
cmd.CommandText = "DELETE FROM YourTableName where id=" + indexDataTable;
cmd.Connection.Open();
cmd.ExecuteNonQuery();
cmd.Connection.Close();
}
Table.Rows[indexDataGridRow].Delete();
Table.AcceptChanges();
dataAdapter.Update(Table);
}
INSERT INTO tbl_name (a,b,c)
VALUES
(1,2,3),
(4,5,6),
(7,8,9);



Если у меня нет аналитического мышления
со временем и практикой код станет лучше?
Или лучше бросить мучить комп и бросать ?



BindingList<string> list = new BindingList<string>();
list.ListChanged += new ListChangedEventHandler(list_ListChanged);
void list_ListChanged(object sender, ListChangedEventArgs e) {
switch (e.ListChangedType){
case ListChangedType.ItemAdded:
break;
case ListChangedType.ItemChanged:
break;
case ListChangedType.ItemDeleted:
break;
case ListChangedType.ItemMoved:
break;
// some more minor ones, etc.
}
}
import re
import pandas as pd
from io import StringIO
srv_data = "A[1]=[1765540,14,2799,4790,'Ts','MSC','2019,8,7,21,00,00',-1,3,2,1,2,1,1,1,2,'20','13','','',82,'','',8,0];"\
"A[2]=[1706041,83,4134,19230,'3DF','rSC','2019,8,7,21,00,00',-1,3,1,2,0,0,0,0,0,'14','8','','',66,'','',0,0];"
csv_data = '\n'.join(re.findall('=\[(.+?)\];', srv_data))
# Вариант без регулярок:
# csv_data = '\n'.join(line.split('=')[1].strip('[]') for line in srv_data.split(';') if line)
df = pd.read_csv(StringIO(csv_data), quotechar="'", header=None)
import pandas as pd
data = "A[1]=[1765540,14,2799,4790,'Ts','MSC','2019,8,7,21,00,00',-1,3,2,1,2,1,1,1,2,'20','13','','',82,'','',8,0];"\
"A[2]=[1706041,83,4134,19230,'3DF','rSC','2019,8,7,21,00,00',-1,3,1,2,0,0,0,0,0,'14','8','','',66,'','',0,0];"
A = {}
exec(data) # Потенциально опасная операция, т.к. в ответе сервера может быть вредоносный код
pd.DataFrame(A.values())

А что делать, если элементы постоянно добавляются? Т.е я убрал 2 элемента, добавились еще 2 и так до бесконечности. Каким образом добраться до самого нижнего элемента?



