Задача:
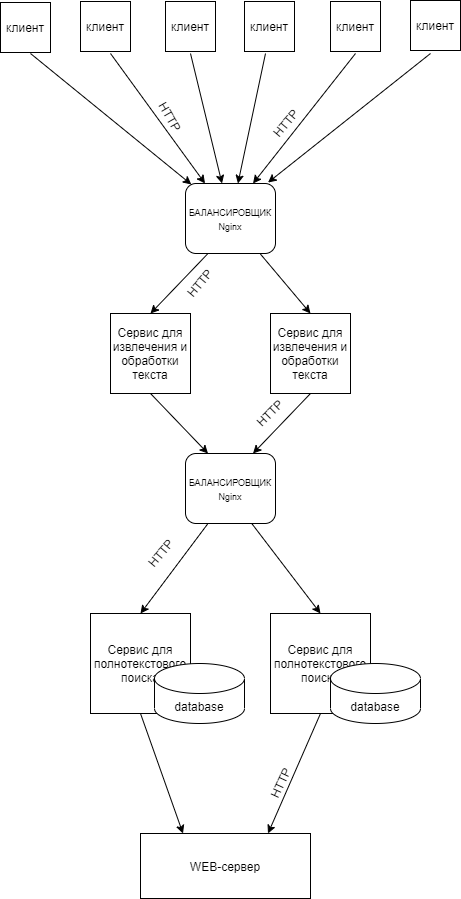
Спроектировать следующий сервис по описанию. Есть N рабочих мест пользователей, на которых установлены агрегаторы текстовых данных. Данные поступают на сервера и проходят обработку на извлечение текста для дальнейшего полнотекстового поиска. Сервис должен масштабироваться.
За основу я взял микросервисную архитектуру. При этом клиенты только отправляют данные и не ожидают никакого ответа. Аналогично и промежуточные сервисы. Масштабирование в моей схеме предполагается за счет повышения производиельности наиболее нагруженных микросервисов (с изменением их "веса" у балансировщика), либо за счет увеличения их количества. Web-сервер в конце схемы это просто пример конечного пользователя. Там может быть что угодно.





 Простой
Простой
 Простой
Простой
 Простой
Простой
 Простой
Простой
 Простой
Простой


