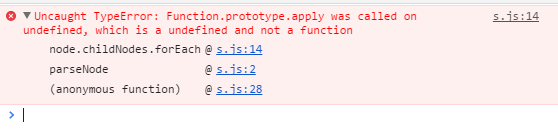
innerHTML, а узлы, DOM Nodes, рекурсивно. Из них рассматривать только текстовые, и менять в них.
Средний
Простой
Простой