Начнем с того что привело к этому обширному вопросу. Вот эта картинка:
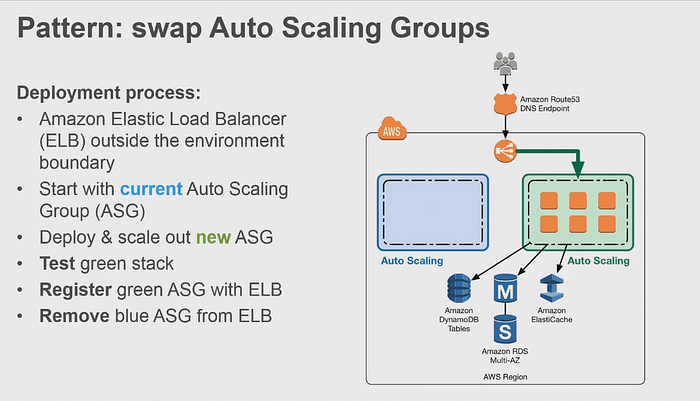
В отличии от вишеуказаной схемы. На данный момент у меня вместо автоскейлинг групы заменяется launch конфигурация с новым ami образом. После деплоя новой инфры внезависимости от значения:
deregistration_delay = 300
Ресурса:
resource "aws_lb_target_group" "lb_tg_name" {
name = "${var.env_prefix}-lb-tg"
vpc_id = var.vpc_id
port = "80"
protocol = "HTTP"
deregistration_delay = 300
stickiness {
type = "lb_cookie"
}
health_check {
path = "/"
port = "80"
protocol = "HTTP"
healthy_threshold = 3
unhealthy_threshold = 3
interval = 30
timeout = 5
matcher = "200-308"
}
tags = {
Name = "app-alb-tg"
Env = var.env_prefix
CreatedBy = var.created_by
}
}
Таргет група тут же присваиет старой машине статус draining и выдает 503 код страницы. И это несмотря на то, что предыдущая машина (ec2) еще жива и способна отвечать на запросы.
Так мы "лежим" примерно с минуту пока не подымится новая машинка и сможет отвечать на запросы.
1) Куда копать чтобы все было плавно и без всяких 503?
2) Может нужно не launch конфигурацию менять, а еще и autoscaling групу как это сделать?


 Простой
Простой
 Простой
Простой
 Средний
Средний
 Простой
Простой







