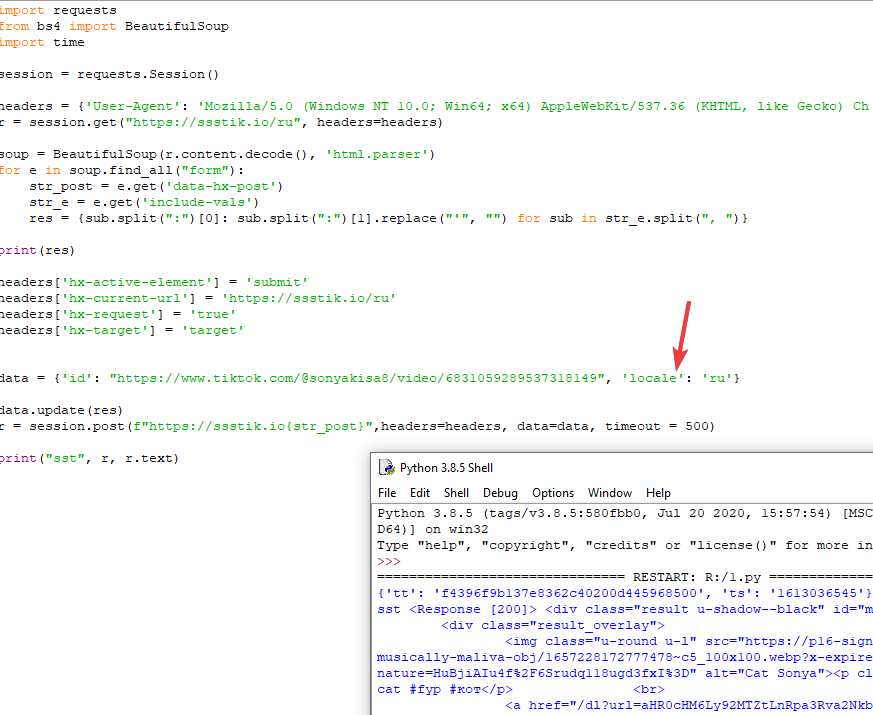
import requests
from bs4 import BeautifulSoup
from fake_useragent import UserAgent
import time
session = requests.Session()
headers = {'User-Agent': UserAgent().chrome}
r = session.get("https://ssstik.io/ru", headers=headers)
soup = BeautifulSoup(r.content.decode(), 'html.parser')
for e in soup.find_all("form"):
str_post = e.get('data-hx-post')
str_e = e.get('include-vals')
res = {sub.split(":")[0]: sub.split(":")[1].replace("'", "") for sub in str_e.split(", ")}
data = {'id': "https://www.tiktok.com/@sonyakisa8/video/6831059289537318149", 'local': 'ru'}
data.update(res)
r = session.post(f"https://ssstik.io{str_post}",headers=headers, data=data, timeout = 500)
print("sst", r, r.content)headers['hx-active-element'] = 'submit'
headers['hx-current-url'] = 'https://ssstik.io/ru'
headers['hx-request'] = 'true'
headers['hx-target'] = 'target'