
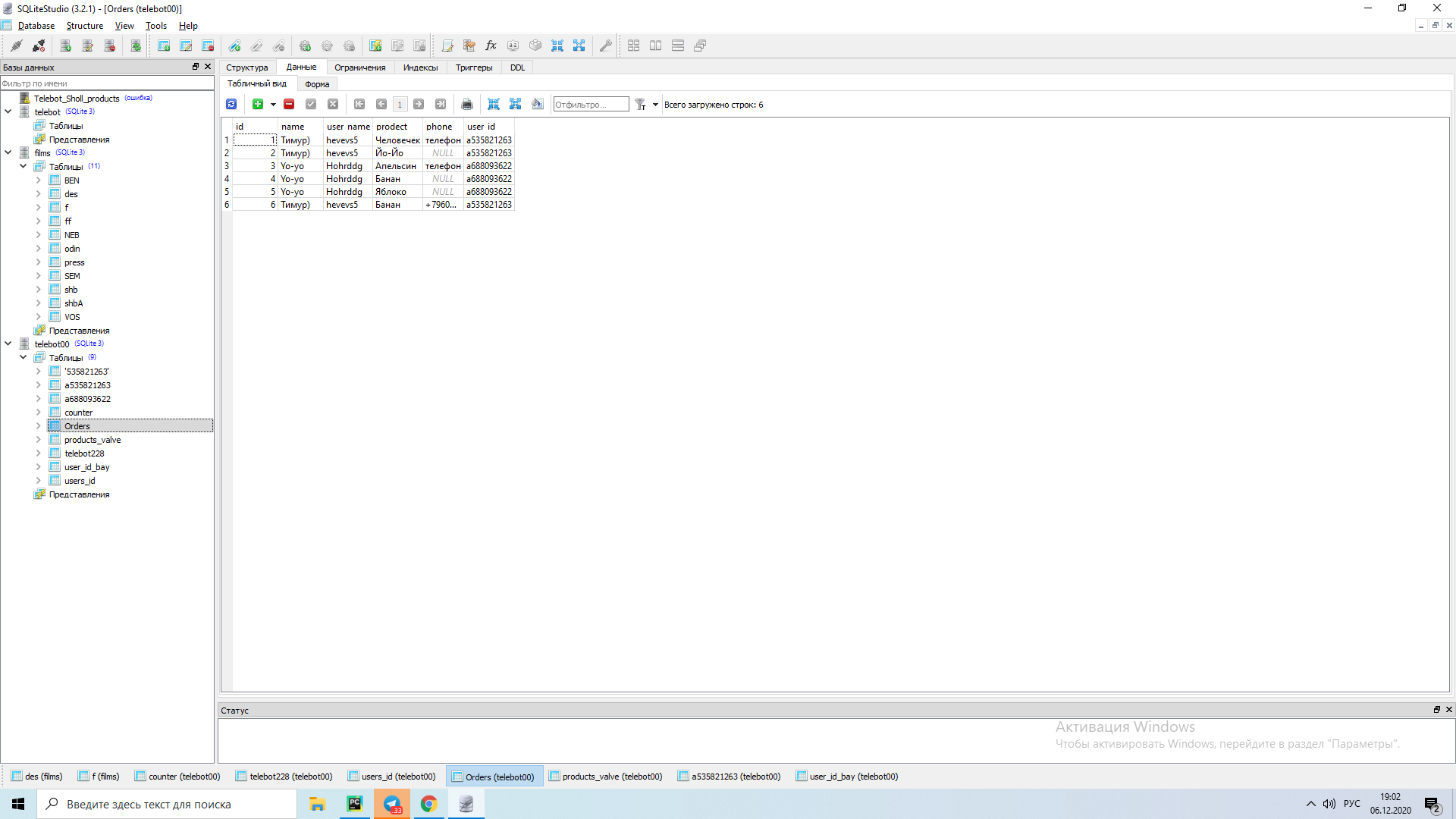
 как мне нужно изменить мой код чтобы был примерно вот такой вывод ПРИМЕР: Тимур) hevevs Человечек, Йо-Йо , банан И тут номер телефона и так-же с другим юзером ПРИМЕР: Yo-yo , Horddg Апельсин 2шт, Банан Яблоко 2шт, Номер телефона я хочу чтобы всё было по порядку и одинаковые слова и имена не повторялись кроме продуктов вот мой код но он рабочий не не так как я хочу
как мне нужно изменить мой код чтобы был примерно вот такой вывод ПРИМЕР: Тимур) hevevs Человечек, Йо-Йо , банан И тут номер телефона и так-же с другим юзером ПРИМЕР: Yo-yo , Horddg Апельсин 2шт, Банан Яблоко 2шт, Номер телефона я хочу чтобы всё было по порядку и одинаковые слова и имена не повторялись кроме продуктов вот мой код но он рабочий не не так как я хочуcon = sqlite3.connect("telebot00.db")
cur = con.cursor()
count_back = 0
order = 'Orders'
back_result = cur.execute(f"""SELECT * FROM {order}""").fetchall()
for back_elem in back_result:
user_id_bay = back_result[1]
count_back = count_back + 1
back = back + str(count_back) + ') '
back = back + back_elem[2]
back = back + ' ,'
back = back + back_elem[3]
back = back + ' ,'
back = back + str(back_elem[4])SELECT name, tel, product, COUNT(product)
FROM order
WHERE user_id=....
GROUP BY name, product