В тесте нужно алгоритмически показать: Как именно можно создать 3 кластера похожих по написанию слов из следующего ниже списка слов:
1. ком
2. лом
3. ром
4. сок
5. сом
6. сор
7. соль
8. лось
При том, что "вес" каждого слова до кластеризации должен быть уникальным.
-----
PS: без использования готовых библиотек и встроенных функций языка программирования, если ответ будет представлен в виде кода.
xmoonlight, я на самом деле далеко не великий специалист в данном вопросе, и даже возможно что совершенно неправильно понял суть вопроса. Просто предложу вариант как его вижу я:
1. Создаем матрицы признаков для каждого из слов, Для этих целей можно использовать различные подходы. Но мне пока приходит на ум расстояния между слов, рассчитанные разными методами, например такими как (взяты из npm пакета natural):
- Hamming distance
- Jaro–Winkler
- Levenshtein
- Dice's co-efficient
2. Используем методы кластерного анализа для определения устойчивых групп на основе собранных матриц признаков. (вот такую реализацию нашел https://github.com/typeetfunc/claster_analysis, навскидку должна подойти)
Что по поводу сторонних библиотек, то просто посмотреть в них реализацию методов, может появятся мысли как сделать их так сказать лайтверсию.
Что он делает? K-means создает k количество групп из набора объектов таким образом, чтобы члены этой группы были больше похожи. Это популярный метод кластерного анализа для изучения набора данных.
Погодите, что такое кластерный анализ? Кластерный анализ — это семейство алгоритмов, предназначенных для формирования групп, где члены этих групп похожи друг на друга сильнее, чем на тех, кто в этой группе не состоит. Кластеры и группы являются синонимами в мире кластерного анализа.
А можно пример? Ну конечно. Предположим, у нас есть набор данных пациентов. В кластерном анализе они называются признаками. О каждом из пациентов нам известны различные факты: возраст, пульс, кровяное давление, уровень холестерина, и т.д. Это вектор характеристик, представляющий пациента.
Смотрите:
О векторе характеристик можно думать, как о списке известных нам чисел, связанных с пациентом. Этот список также может быть интерпретирован как координаты в многомерном пространстве. Пульс может быть одним измерением, кровяное давление — другим и так далее.
Вы, наверное, задаетесь вопросом:
Учитывая этот набор векторов, как же мы сгруппируем вместе пациентов, близких по возрасту, с похожими значениями пульса, кровяного давления и т.д.?
Хотите узнать лучшее свойство k-means?
Вы лишь задаете количество нужных вам кластеров. K-means заботится обо всем остальном.
Как же k-means заботится обо всем остальном? У k-means есть много вариаций для оптимизации определенных типов данных.
Не вдаваясь в подробности, это происходит примерно так:
k-means выбирает точки в многомерном пространстве для каждого из k кластеров. Их называют центроидами.
Каждый из пациентов будет ближе всего к одному из этих центроидов. Скорее всего, не все из них будут ближе всего к одному и тому же центроиду, так что сформируется несколько кластеров вокруг соответствующих центроидов.
У нас теперь есть k количество кластеров, и каждый из пациентов принадлежит к одному из них.
k-means после этого находит центр каждого кластера, опираясь на членов этих кластеров (используя векторы характеристик пациентов).
Этот центр становится новым центроидом кластера.
Так как центроид теперь в другом месте, пациенты могут оказаться ближе к другому центроиду. Другими словами, они могут перейти в другой кластер.
Шаги 2-6 повторяются до тех пор, пока центроиды больше не изменяются. Это называется конвергенцией.
Это обучение с учителем или без? Большинство считают k-means самообучающимся алгоритмом. Кроме указания количества кластеров, k-means «узнает» кластеры сам по себе, без какой-либо информации о том, к какому кластеру принадлежит тот или иной признак. K-means может, тем не менее, быть полуконтролируемым.
Почему стоит попробовать k-means? Мне кажется, это понятно.
Главным преимуществом k-means является его простота. То, что он прост в реализации, означает, что он обычно быстрее и эффективнее других алгоритмов, особенно при работе с большим набором данных.
К тому же, k-means можно использовать для предварительного кластерного анализа огромных наборов данных, чтобы потом воспользоваться более затратным алгоритмом кластерного анализа на самих кластерах. K-means также может изучать упущенные связи в наборе данных путем резкого изменения k.
Но не все так радужно:
Двумя главными недостатками k-means являются его чувствительность к выбросам и первоначальному выбору центроидов. И последнее, k-means был разработан для работы с непрерывными данными. Вам придется воспользоваться некоторыми уловками для того, чтобы работать с дискретными данными.
Где он используется? Огромное количество реализаций k-means доступны в сети:
Apache Mahout
Julia
R
SciPy
Weka
MATLAB
SAS
Если же деревья решений и кластеризация не произвели на вас впечатление, вам гарантированно понравится следующий алгоритм…
описание взято тут. Там же есть описания еще 9-и методов кластерного анализа, а реализация на конкретном ЯП гуглится по названию.
xmoonlight, k-means же работает по нескольким признакам?
А можно пример? Ну конечно. Предположим, у нас есть набор данных пациентов. В кластерном анализе они называются признаками. О каждом из пациентов нам известны различные факты: возраст, пульс, кровяное давление, уровень холестерина, и т.д. Это вектор характеристик, представляющий пациента.
просто сформируйте для каждого слова вектор из N признаков
[значение признака 1, значение признака 2, ...., значение признака N]
xmoonlight, ясно. Но я так понимаю что задание на кластерный анализ не может требовать от вас изобрести свой метод, речь наверняка идет о том чтобы найти и использовать один из существующих, наиболее подходящий под задачу?
Роман, всё может, да ещё как... Например, чтобы отсеять всех тех, кто научился только шаблонному анализу данных, нужно проверить насколько человек понимает то, что он делает в принципе на самом низком уровне абстракции (что вполне логично).
xmoonlight, сейчас попробую накидать реализацию, как ее вижу я, совершенно не привязанную к академическим знаниям.
Для этого мне понадобится некоторая информация от вас.
При том, что "вес" каждого слова до кластеризации должен быть уникальным.
1. Про какой вес говориться?
2. Что значит уникальный (можно ли считать что следующие 2 веса уникальны 0.59999 и 0.6?
3. Как этот вес может измениться после кластеризации?
Как именно можно создать 3 кластера похожих по написанию слов из следующего ниже списка слов:
4. Почему именно 3 кластера?
5. Может ли меняться набор слов?
6. Меняется ли требуемое количество кластеров на выходе при изменении набора слов?
7. Должны ли учитываться порядковые номера слов в списке (числовые индексы) при решении задачи?
8. Считать ли строчные и прописные буквы одинаковыми?
xmoonlight, я не понимаю как это сделать. Задание реально бредовое, или вырвано из контекста.
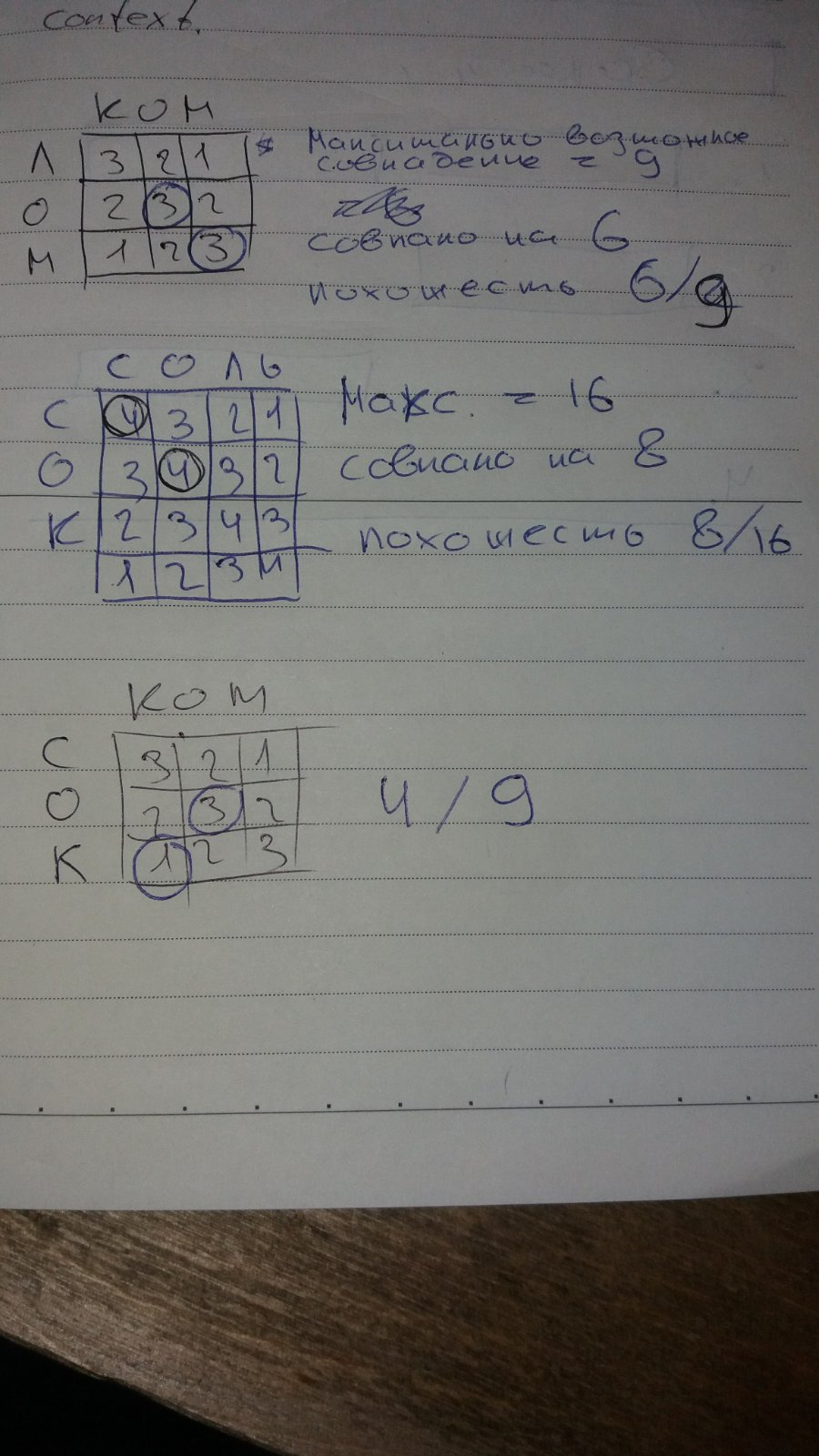
Посудите сами. Попытаемся вручную разделить их на 3 кластера(группы)
в первую группу идут:ком, лом, ром, сом
во вторую группу идут: сок, сом, сор и возможно соль
в третью группу идет: лось
итак имеем одну, неразрешимую коллизию - слово сом, которая равноудалена от слов как первой так и второй групп, к какой группе его отнести? к первой, второй, а может сразу к обоим группам? Математически оно одинаково близко к обоим группам.
Возможно в контексте задания (например на лекции, после которой это задание и было дано) было сказано, что вес совпадения букв в начале слова выше чем в конце?
PS: Вот написал небольшую взвешивалку похожести слов, может у вас какая идея придет.
код
function detSimilarity(w1, w2) {
const len = Math.max(w1.length, w2.length);
let summ = 0;
for (let i1 in w1) {
c1 = w1[i1];
let d = len;
for (let i2 in w2) {
c2 = w2[i2];
if (c1 == c2) {
const t = Math.abs(i1 - i2);
if (t < d) d = t;
}
}
summ += len - d;
}
return summ / Math.pow(len, 2);
}
НО какие логические основания для этого могут быть?
чтобы это понять, нужно в столбик вывести ВСЕ "веса" слов и убедиться, что они ВСЕ уникальны. А потом - делать выводы по тому, насколько корректны их расстояния между собой.
Роман, если бы были коллизии, то и слова были бы одинаковые. Задание дала крупная организация для проверки знаний исполнителя по своему проекту по анализу текстовых данных. Как бы первичный отборочный фильтр (как я понял).
Если бы небыло условия разбить на группы по схожести написания задача была бы тривиальной. А так они в условии дают жесткое ограничение на используемые признаки а данные содержат неоднозначность по этому умловию.
xmoonlight, и вот еще мысль появилась, как данную неоднозначность разрешить. Создать матрицу 33х33 в которой будут коэффициенты похожести написания самих букв между собой.
xmoonlight, вот еще вариант. Класифицирующая нейросеть, обученная определять похожесть. Обучающую выборку прийдется искать или делать самому. Так как инс не дают точный результат, то ее использование и даст некоторую степень расхождения в оценке принадлежности к разным группам слов. Но это уже по сути будет подтасовка/жульничество.
Кластеризация (обучение без учителя) отличается от классификации (обучения с учителем) тем, что метки объектов из обучающей выборки yi изначально не заданы, и даже может быть неизвестно само множество Y
.
Решение задачи кластеризации объективно неоднозначно по ряду причин:
Не существует однозначного критерия качества кластеризации. Известен ряд алгоритмов, осуществляющих разумную кластеризацию "по построению", однако все они могут давать разные результаты. Следовательно, для определения качества кластеризации и оценки выделенных кластеров необходим эксперт предметной области;
Число кластеров, как правило, заранее не известно и выбирается по субъективным критериям. Даже если алгоритм не требует изначального знания о числе классов, конкретные реализации зачастую требуют указать этот параметр[1];
Результат кластеризации существенно зависит от метрики. Однако существует ряд рекомендаций по выбору метрик для определенных классов задач.[2].
таким образом можно выбрать любые признаки, главное обосновать их логичность/разумность. То есть мой вариант несимметричности по второстепенной оси матрицы вполне годен при условии, что будет обоснование утверждения, что совпадение начала слов важнее чем совпадение конца слов. Это можно попытаться доказать на основе анализа механизмов восприятия печатных слов человеком. Думаю что при желании можно нагуглить результаты исследований на данную тему и на них опереться.
Роман, это, конечно, занятно, но мало применимо к данной задаче. И это уже следующий, 2-й шаг.
Ок.
А что делать с первым?!
Как сделать так, чтобы все слова имели уникальные "веса" до кластеризации так, чтобы по ним можно было различать схожесть написания также, как и слова, написанные буквами?
Как сделать так, чтобы все слова имели уникальные "веса" до кластеризации
да очень просто.
Вариант 1.
N мерная система координат. Где N - предполагаемое максимально возможное число букв в слове.
Ттаким образом, любое слово можно выразить вектором, в котором ось - номер позиции буквы в слове, а значение по оси - индекс в алфавите буквы из этой позиции
Вес можно интерпретировать как длину данного вектора
Вариант 2.
N мерная система координат. Где N - число букв в алфавите.
Ттаким образом, любое слово можно выразить вектором, в котором для каждой оси - значением будет либо 0, либо, если буква была в слове то 1. При таком подходе слова мир и рим будут иметь одинаковый вектор. Чтобы этого избежать, можно замнить 1 на индекс буквы в слове.
Вес можно интерпретировать как длину данного вектора
В обоих случаях есть вероятность (хоть и небольшая), что у разных слов при различных направлениях их вектора длинна вектора будет одинаковой. В любом случае направление в котором можно поразмыслить я дал. Сам жэ еще немного подумаю, как устранить озвученный недостаток.
xmoonlight, если честно, вообще не понимаю зачем тут самостоятельный, ни к чему не привязанный вес слова нужен. На мой взгляд достаточно векторов. И вот они (вектора) как раз у каждого слова уникальны. тогда почти любой метод кластеризации можно будет использовать заменив обычную арифметику на векторную.
Если же имеется ввиду уникальный вес каждой связи между каждой парой слов то тут думать надо.
xmoonlight, вот надумал способ совместить вектор и вес.
Берем 34-ную систему счисления, в которой условно счислительный базис (34) это числа от нуля до 33 (номер буквы в алфавите). Таким образом получим:
вектор по варианту 1.
вес это представление слова в виде числа. Например слово aa будет представленно как 1*34+1, слово бa как 2*34+1, слово aб как 1*34+2. По сути тот же вектор, только запакованный, но так как это обычное число - то оно же и вес. Притом вес уникальный для каждого уникального слова. Расстояние можно считать как между векторами, так и простой арифметикой между весами. Признаками соответственно будут разницы между условных "едениц", "десятков", "сотен" и т.д.
xmoonlight, ну в первом варианте вектора у каждого из слов будут уникальны, во втором уникальны с поправкой "чтобы этого избежать, можно заменить 1 на индекс буквы в слове.". А в комментарии выше показал как для первого варианта сделать уникальным не только вектор но еще и вес.
xmoonlight, если возник вопрос почему базис не 33 а 34, потому чтобы слова "a", "аа", "ааа" были не равны между собой. Расстояния рассчитанные между векторами варианта 1 и между представлениями этих векторов в системе счисления 34 будут конечно разными в числовом выражении, но и те и другие сохранят взаимосвязь между словами.
Роман, это всё применимо в сжатии данных, которые открыты более 60 лет назад, а к данной задаче это не применимо и тупо, когда можно просто всё решить имея на руках то, чего достигла наука, а не Ваши сраные калькуляторы.


 Простой
Простой
 Простой
Простой