Да, надо было сначала хорошо обдумать самому, а потом уже спрашивать. Как-то спонтанно появилась мысль спросить помощи у общества, в результате имеем то, что имеем :)
Попытка номер 2:
Задача: Имеется некоторый идеальный шкальный профиль (просто последовательность чисел по разным шкалам), с которым надо сравнить результат, полученный испытуемым и получить процент сходства.
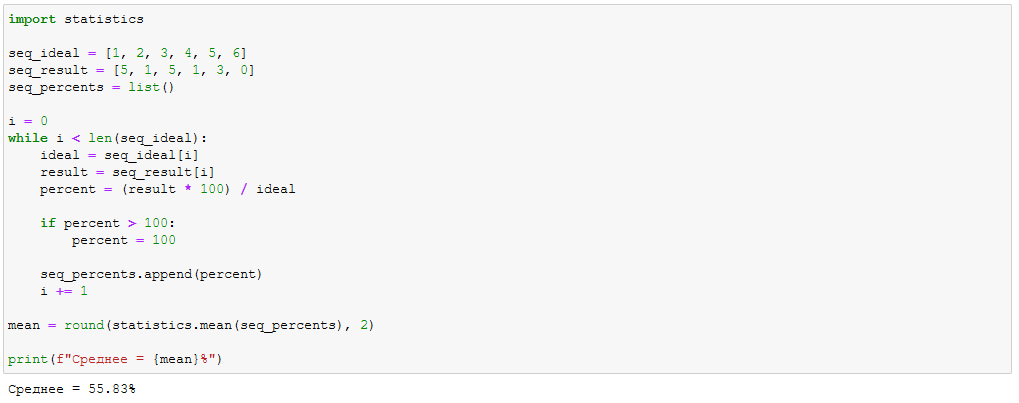
На этом имеющиеся вводные и закончились. Чтобы ограничить количество проблем, можно попробовать ограничивать результат с одной стороны, т.е. если испытуемый набрал 5, а в идеале требуется только 3, то считаем, что критерий он полностью удовлетворил и это 100%.
Получилось что-то подобное, но не оставляет ощущение, что это немного не то, что запрашивалось, т.к. решение ну совсем уж в лоб:

Остаются, правда, вопросы быстродействия, т.к. в результате испытуемого должно быть 90-100 чисел и их надо будет сравнить с приблизительно 300 другими последовательностями и выплюнуть результат. Есть подозрение, что недорогой vps подавится при выдёргивании каждой последовательности из бд, если к нему обращаться более-менее регулярно.
-------------------
Привет.
Есть несложная, на первый взгляд, задача: сравнить две последовательности чисел (в массивах, например, но не принципиально, можно хоть в чём) на их схожесть в %.
Т.е. дано:
Последовательность 1 - 1 2 3 4 5 6
Последовательность 2 - 4 3 5 6 1 1
Сравнить надо не в лоб, сколько чисел совпадают, а насколько каждая позиция последовательности 2 отличается такой же в последовательности 1 и посчитать % сходства с учётом этого. Максимально возможное значение для каждой позиции известно заранее.
Что-то готовое подходящее можно найти или копать в сторону самостоятельного придумывания? Покурил difflib, вроде не подойдёт.