Всем привет!
Недавно встретилась довольно простая задача: дан массив целых чисел и число "a", нужно найти первое ближайшее к "a" число в массиве.
Сразу пришел на ум не самый оптимальный вариант - посчитать для всех чисел в массиве модуль разности с a, найти минимальный и за третий проход остановиться при совпадении.
Потом понял, что решить задачу можно еще как минимум 3 способами (через key в min, через reduce, через простой самописный алгоритм) и решил измерить время расчета для каждого способа.
def time_deco(func):
@wraps(func)
def wrapper(*args, **kwargs):
start = datetime.now()
res = func(*args, **kwargs)
return (datetime.now() - start).total_seconds()
return wrapper
@time_deco
def with_min(a, l):
return min(l, key=lambda x: abs(a-x))
@time_deco
def with_reduce(a, l):
return reduce(lambda x, y: x if abs(a-y) >= abs(a - x) else y, l)
@time_deco
def with_map(a, l):
z = min(map(lambda x: abs(a-x), l))
for i in l:
if abs(a-i) == z:
return i
@time_deco
def traditional_way(a, l):
value = l[0]
i = abs(a - value)
for item in l:
if abs(a - item) < i:
i = abs(a - item)
value = item
return value
my_funcs = [with_min, with_reduce, with_map, traditional_way]
a = random.randint(0, 500000000)
random_list_100 = [random.randint(0, 100) for _ in xrange(100)]
random_list_100k = [random.randint(0, 100000) for _ in xrange(100000)]
random_list_1kk = [random.randint(0, 1000000) for _ in xrange(1000000)]
random_list_100kk = [random.randint(0, 100000000) for _ in xrange(100000000)]
random_list_200kk = [random.randint(0, 200000000) for _ in xrange(200000000)]
random_list_300kk = [random.randint(0, 300000000) for _ in xrange(300000000)]
for_df = dict()
for func in my_funcs:
for_df[func.__name__] = [func(a, random_list_100),
func(a, random_list_100k),
func(a, random_list_1kk),
func(a, random_list_100kk),
func(a, random_list_200kk),
func(a, random_list_300kk),
]
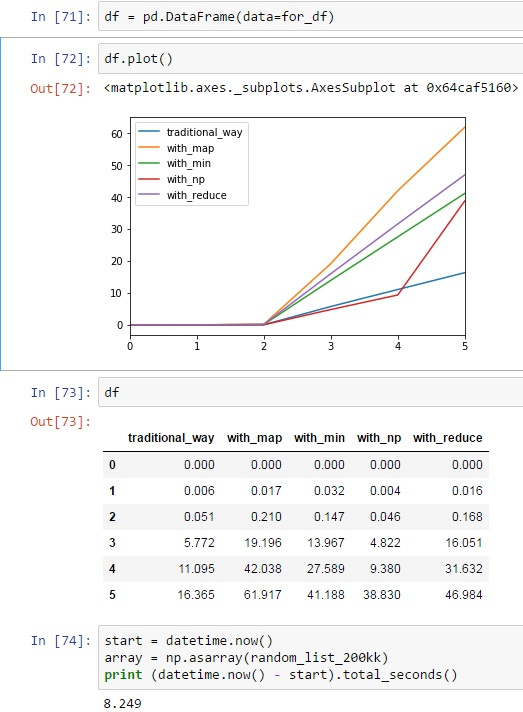
df = pd.DataFrame(data=for_df)
Результаты оказались довольно странными для меня:
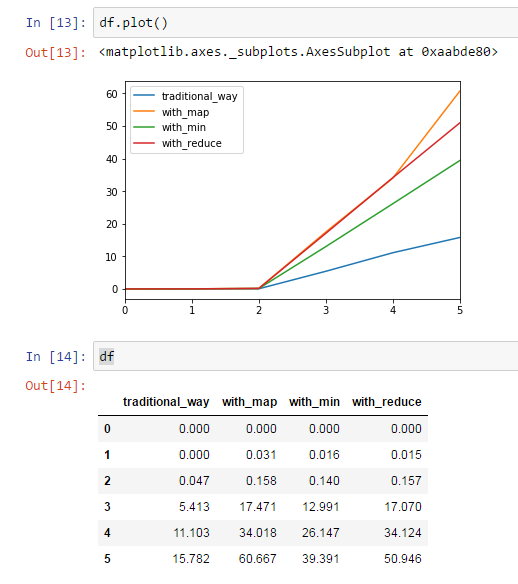
Я не могу понять, почему min и reduce считаются в разы дольше чем самописный вариант, ведь нахождение нужного элемента во всех случаях производится за 1 проход, а min, на сколько я понимаю, работает так же как я расписывал в traditional_way.