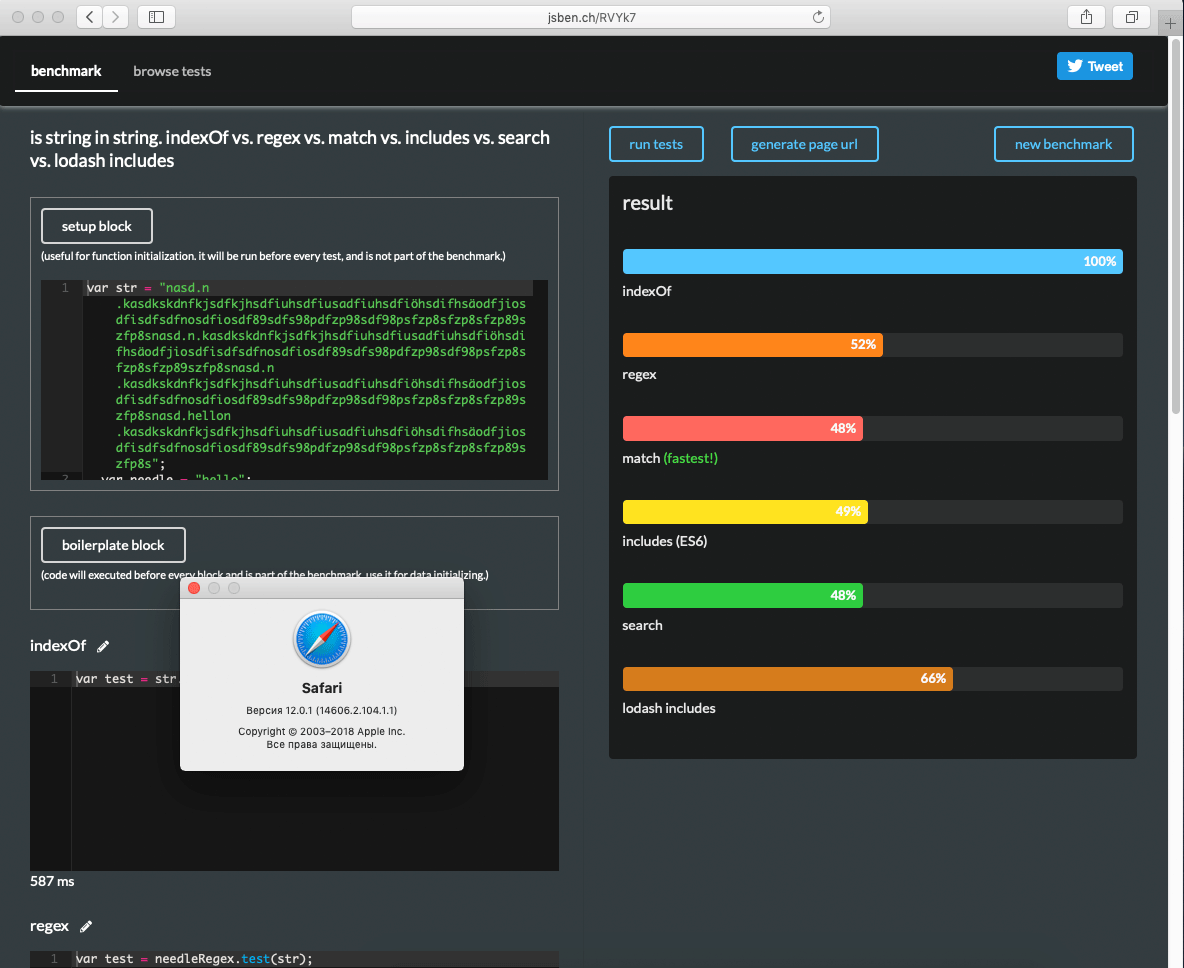
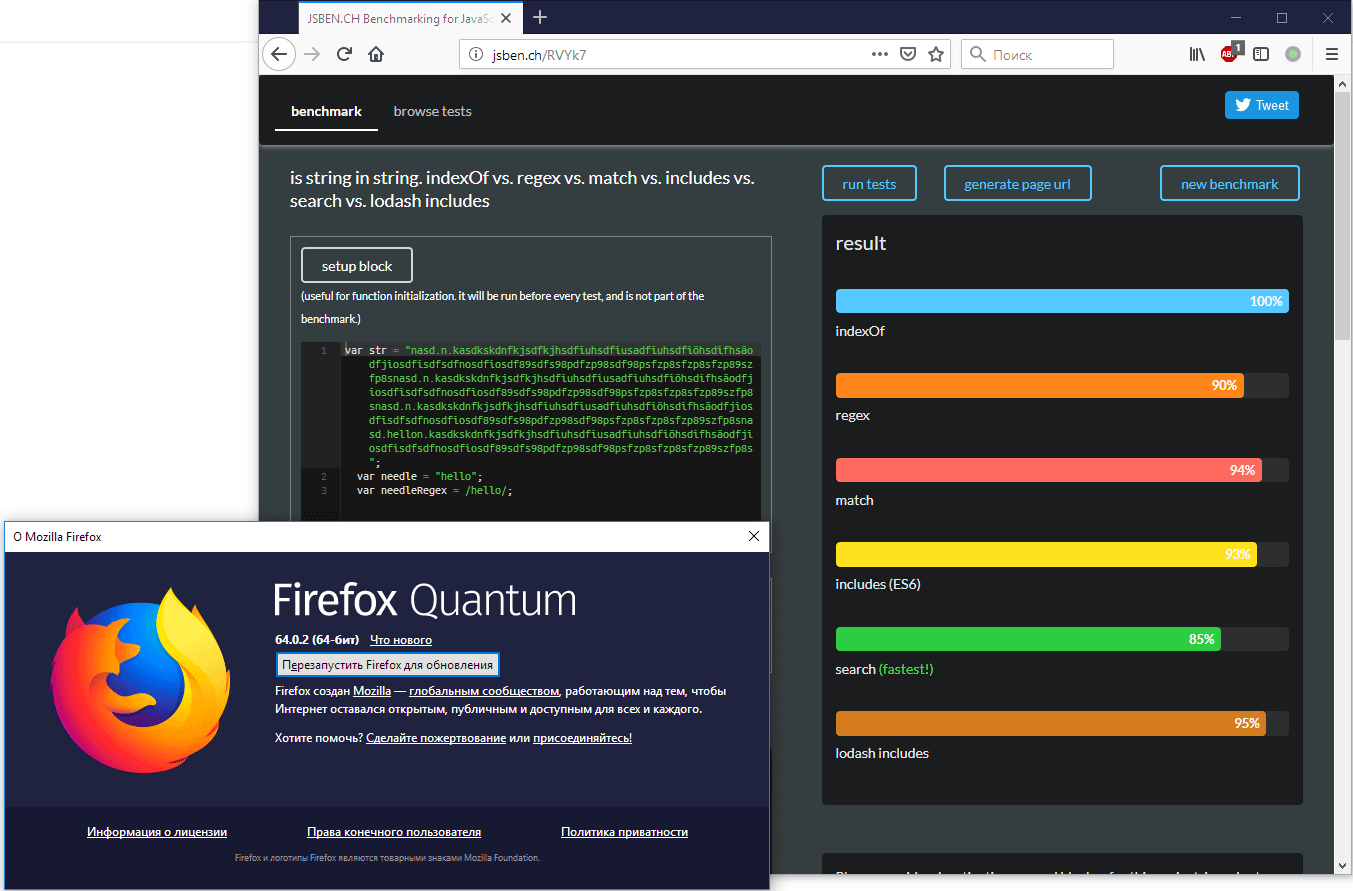
indexOf: 0.190ms
test: 0.013ms
match: 0.030ms
includes: 0.027ms
search: 0.029ms Средний
Сложный
Сложный
Средний
Средний
Сложный
Сложный
Средний