
import requests
from bs4 import BeautifulSoup
def trade_spiders (max_page):
page = 1
while page <= max_page:
url = 'https://www.toster.ru/questions' + str(page)
source_code = requests.get(url)
plain_text = source_code.content
soup = BeautifulSoup(plain_text, 'html.parser')
spider = soup.find('h2').text
main_title = soup.find_all(('a', {"class": "question__title-link question__title-link_list"}))
print(spider)
print(main_title)
page+=1
trade_spiders(1)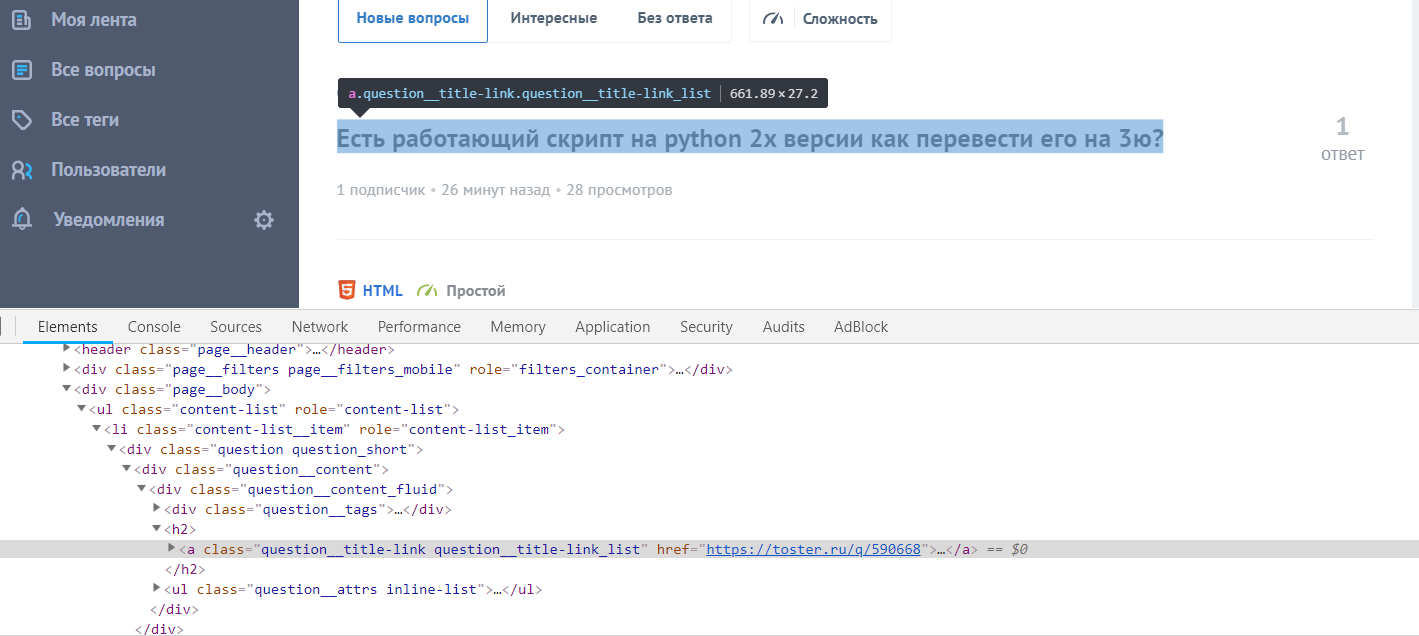
import requests
from bs4 import BeautifulSoup
def trade_spiders (max_page):
page = 1
while page <= max_page:
url = 'https://toster.ru/questions/latest?page=' + str(page)
source_code = requests.get(url)
soup = BeautifulSoup(source_code.text, 'html.parser')
main_title = soup.find_all('a', {"class": "question__title-link"})
for title in main_title:
print(title.text.strip(), title.get('href')) # Первый элемент - название, второй - ссылка.
page+=1
trade_spiders(1)