import difflib
arr = [
{"_id": 1, "list_word_int": [189, 114, 188,
90, 2, 68, 96, 0, 250, 168, 150, 126]},
{"_id": 2, "list_word_int": [224, 26, 56,
153, 139, 128, 126, 220, 190, 137], },
{"_id": 3, "list_word_int": [188, 241, 225,
134, 134, 30, 134, 187, 204, 227, 3]},
{"_id": 4, "list_word_int": [
224, 166, 159, 236, 82, 17, 82, 21, 227, 97], },
{"_id": 5, "list_word_int": [98, 96, 38, 107, 142, 134, 13, 36, 23], }
]
for a in arr:
for b in arr:
if b["_id"] == a["_id"]:
continue
sm = difflib.SequenceMatcher(None, a["list_word_int"],
b["list_word_int"])
ratio = sm.ratio()
print("id= ", a["_id"],
"Сравниваемый id=", b["_id"],
"Коэффициент похожести:", ratio)id= 1 Сравниваемый id= 2 Коэффициент похожести: 0.09090909090909091
id= 1 Сравниваемый id= 3 Коэффициент похожести: 0.08695652173913043
id= 1 Сравниваемый id= 4 Коэффициент похожести: 0.0
id= 1 Сравниваемый id= 5 Коэффициент похожести: 0.09523809523809523
id= 2 Сравниваемый id= 1 Коэффициент похожести: 0.09090909090909091
id= 2 Сравниваемый id= 3 Коэффициент похожести: 0.0
id= 2 Сравниваемый id= 4 Коэффициент похожести: 0.1
id= 2 Сравниваемый id= 5 Коэффициент похожести: 0.0
id= 3 Сравниваемый id= 1 Коэффициент похожести: 0.08695652173913043
id= 3 Сравниваемый id= 2 Коэффициент похожести: 0.0
id= 3 Сравниваемый id= 4 Коэффициент похожести: 0.09523809523809523
id= 3 Сравниваемый id= 5 Коэффициент похожести: 0.1
id= 4 Сравниваемый id= 1 Коэффициент похожести: 0.0
id= 4 Сравниваемый id= 2 Коэффициент похожести: 0.1
id= 4 Сравниваемый id= 3 Коэффициент похожести: 0.09523809523809523
id= 4 Сравниваемый id= 5 Коэффициент похожести: 0.0
id= 5 Сравниваемый id= 1 Коэффициент похожести: 0.09523809523809523
id= 5 Сравниваемый id= 2 Коэффициент похожести: 0.0
id= 5 Сравниваемый id= 3 Коэффициент похожести: 0.1
id= 5 Сравниваемый id= 4 Коэффициент похожести: 0.0import difflib
from functools import lru_cache
from itertools import combinations
arr = [
{"_id": 1, "list_word_int": (189, 114, 188, 90, 2, 68, 96, 0, 250, 168, 150, 126)},
{"_id": 2, "list_word_int": (224, 26, 56, 153, 139, 128, 126, 220, 190, 137)},
{"_id": 3, "list_word_int": (188, 241, 225, 134, 134, 30, 134, 187, 204, 227, 3)},
{"_id": 4, "list_word_int": (224, 166, 159, 236, 82, 17, 82, 21, 227, 97)},
{"_id": 5, "list_word_int": (98, 96, 38, 107, 142, 134, 13, 36, 23)},
]
@lru_cache(maxsize=2 ** 13)
def get_ratio(lst1, lst2):
return difflib.SequenceMatcher(None, lst1, lst2).ratio()
if __name__ == "__main__":
for a, b in combinations(arr, 2):
ratio = get_ratio(a["list_word_int"], b["list_word_int"])
print(
"id= ",
a["_id"],
"Сравниваемый id=",
b["_id"],
"Коэффициент похожести:",
ratio,
)
print(get_ratio.cache_info())import difflib
import multiprocessing as mp
import os
from itertools import combinations, cycle
arr = [
{"_id": 1, "list_word_int": [189, 114, 188, 90, 2, 68, 96, 0, 250, 168, 150, 126]},
{"_id": 2, "list_word_int": [224, 26, 56, 153, 139, 128, 126, 220, 190, 137]},
{"_id": 3, "list_word_int": [188, 241, 225, 134, 134, 30, 134, 187, 204, 227, 3]},
{"_id": 4, "list_word_int": [224, 166, 159, 236, 82, 17, 82, 21, 227, 97]},
{"_id": 5, "list_word_int": [98, 96, 38, 107, 142, 134, 13, 36, 23]},
]
def target(id_, count):
pid = os.getpid()
for i, (a, b) in zip(cycle(range(count)), combinations(arr, 2)):
if i != id_:
continue
ratio = difflib.SequenceMatcher(
None, a["list_word_int"], b["list_word_int"]
).ratio()
print(f"PID: {pid} id={a['_id']} & {b['_id']} ratio={ratio}")
if __name__ == "__main__":
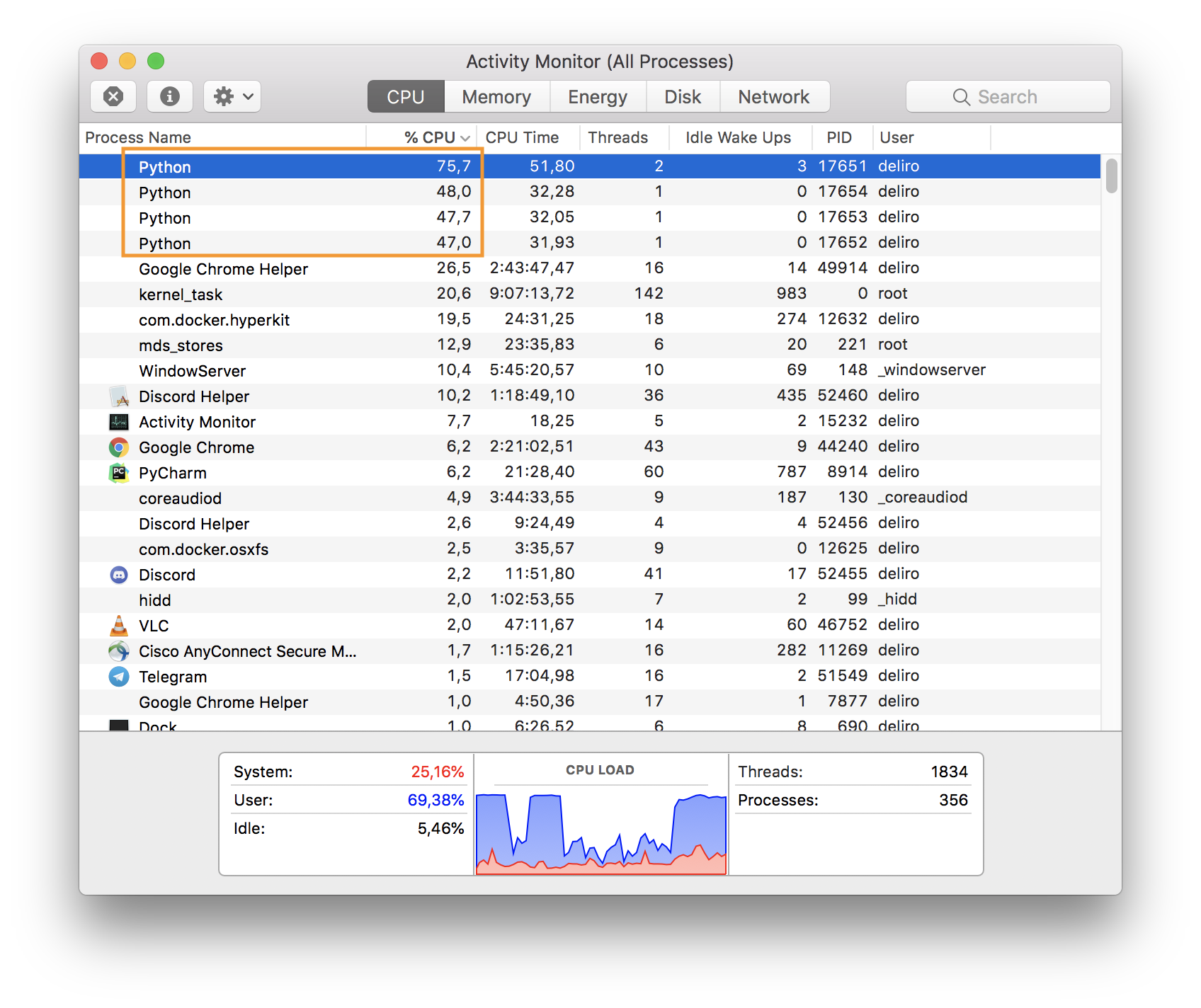
processes = []
for x in range(mp.cpu_count()):
p = mp.Process(target=target, args=(x, mp.cpu_count()))
p.start()
processes.append(p)
for p in processes:
p.join()import difflib
import multiprocessing as mp
import os
from itertools import combinations
arr = [
{"_id": 1, "list_word_int": [189, 114, 188, 90, 2, 68, 96, 0, 250, 168, 150, 126]},
{"_id": 2, "list_word_int": [224, 26, 56, 153, 139, 128, 126, 220, 190, 137]},
{"_id": 3, "list_word_int": [188, 241, 225, 134, 134, 30, 134, 187, 204, 227, 3]},
{"_id": 4, "list_word_int": [224, 166, 159, 236, 82, 17, 82, 21, 227, 97]},
{"_id": 5, "list_word_int": [98, 96, 38, 107, 142, 134, 13, 36, 23]},
]
def queue_creator(q, w_count):
pid = os.getpid()
print("Created queue generator PID", pid)
for a, b in combinations(arr, 2):
q.put((a, b))
for _ in range(w_count):
q.put(("stop", None))
def worker(q):
pid = os.getpid()
print("Created worker PID", pid)
while True:
a, b = q.get()
if a == "stop":
break
ratio = difflib.SequenceMatcher(
None, a["list_word_int"], b["list_word_int"]
).ratio()
print(f"PID:{pid} {a['_id']} & {b['_id']} ratio={ratio}")
if __name__ == "__main__":
queue = mp.Queue()
# 1 воркер на генерацию комбинаций, остальные на обработку
workers_count = (mp.cpu_count() - 1) or 1
q_process = mp.Process(target=queue_creator, args=(queue, workers_count))
q_process.start()
processes = [q_process]
for x in range(workers_count):
p = mp.Process(target=worker, args=(queue,))
p.start()
processes.append(p)
for process in processes:
process.join()
 Простой
Простой
Простой
Простой
Простой
Простой
Простой
Простой