Образец кодирования в Excel
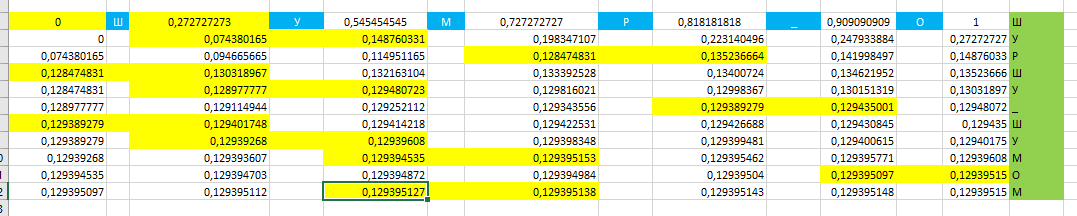
У меня уже есть подсчет частот
import collections
co = collections.Counter()
file_txt = open("test.txt","r", encoding='utf-8')
for line in file_txt:
co.update(line.lower())
total, lo = sum(co.values()), 0
for k, v in co.most_common():
hi = lo + v
print('%f\t%c\t%f' % (lo / total, k, hi / total))
lo = hi
Вывод в консоли
0.000000 ш 0.272727
0.272727 у 0.545455
0.545455 м 0.727273
0.727273 р 0.818182
0.818182 0.909091
0.909091 о 1.000000
Как видно из скриншота, справа идет текст побуквенно
Причем следующий шаг изменяет значения начального и конечного кодируемого символа согласно правилу:
High=Lowold+(Highold-Lowold)*RangeHigh(x),
Low=Lowold+(Highold-Lowold)*RangeLow(x),
где Lowold – нижняя граница интервала,
Highold – верхняя граница интервала
RangeHigh и RangeLow – верхняя и нижняя границы кодируемого символа.
Результатом является число, лежащее слева.
1) Каким образом лучше всего сохранить образец, так как он понадобится при пересчете значений ? Словарь, json ?
2) Как считывать побуквенно текстовый файл, применяя к нему алгоритм АК

