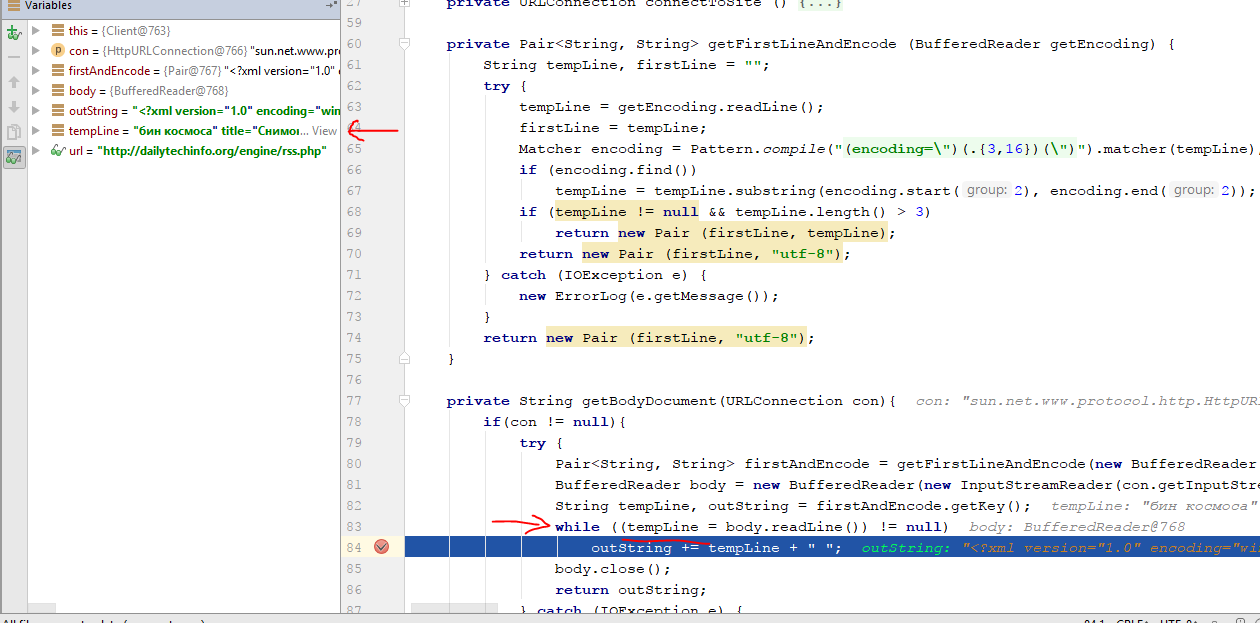
BufferedReader body = new BufferedReader(new InputStreamReader(con.getInputStream(), "utf-8");
String tempLine, outString = "";
while ((tempLine = body.readLine()) != null)
outString += tempLine + " ";
body.close();
return outString;
По умолчанию читаю поток в кодировке utf-8, но могут попасться сайты с другой кодировкой, как ее определить, если ее название не возвращается в Headers?
Пробовал писать отдельный метод и читать первую строку, извлекать название кодировки из тела документа, но в таком случае
body.readLine() выводит текст не со второй строки, а из середины документа, на картинке видно, что tempLine берет инфу явно не из следующей строки: