Доброй ночи, Хабровчане. Как дела?
Мы с товарищем тестируем Кассандра кластер из двух датацентров по пять нод в каждом. Написали небольной скрипт, используя Faker что-бы забить кластер тестовыми данными. Сейчас в базе около 5 миллионов записей.
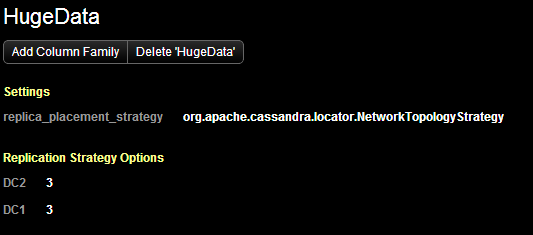
Мы создали keyspace HugeData используя NetworkTopologyStrategy = 3 на каждый ДЦ.
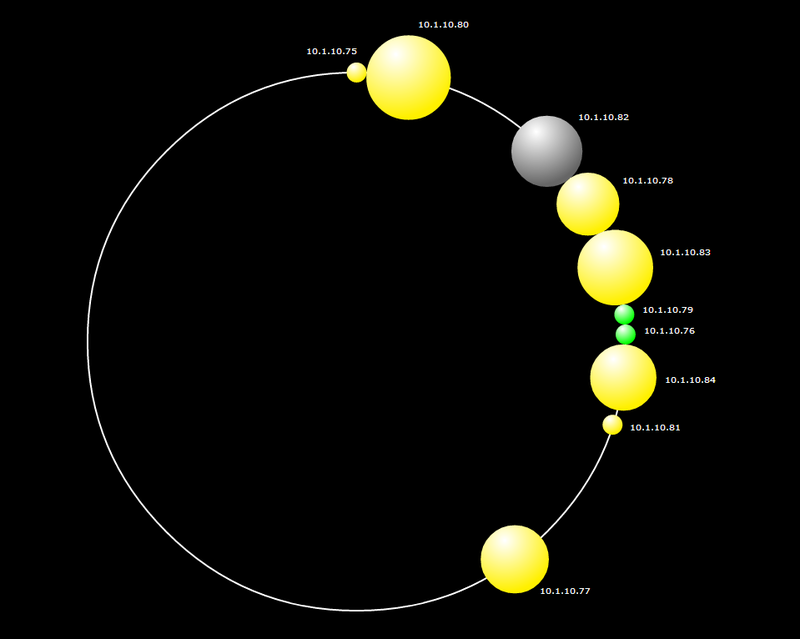
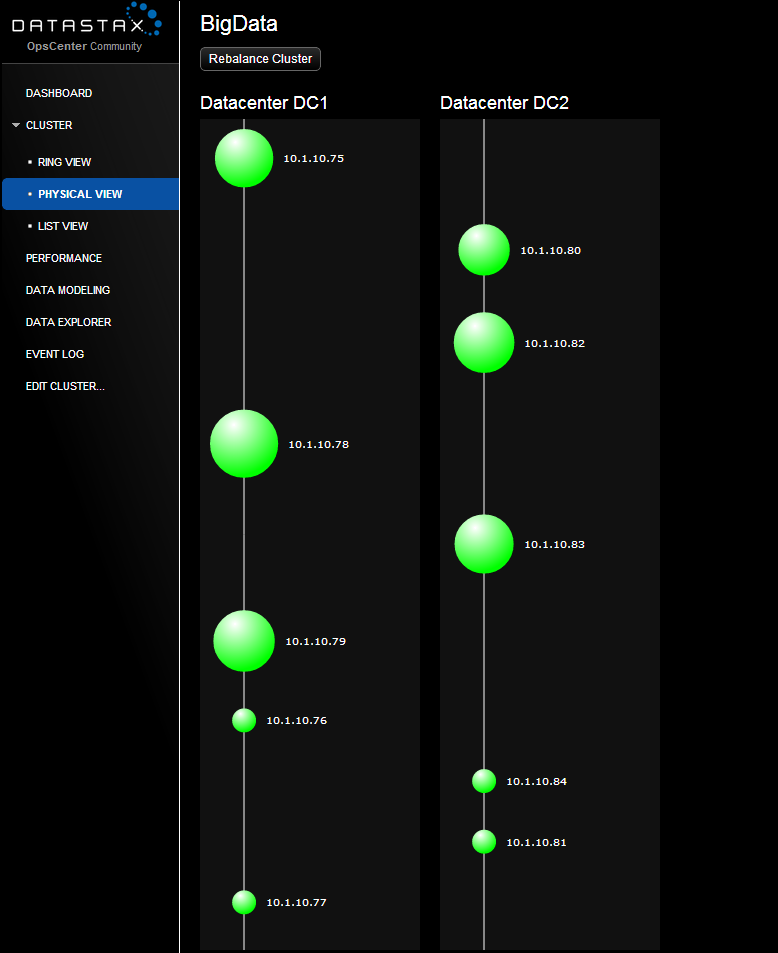
Проблема в том, что мы думали, что данные размажутся равномерно на 10-ти нодах, но на первом скриншоте видно, что только первые 6 забиты данными (оно и понятно, replication factor 3 на каждый ДЦ).
Возможно это из-за того, что кластер не сбалансирован? Почему кассандра забила только 6 нод, а не все 10?
Вот что показывает nodetool satus
[root@dc2rac1cs1 ~]# nodetool -h 10.1.10.75 status
Datacenter: DC1
===============
Status=Up/Down
|/ State=Normal/Leaving/Joining/Moving
-- Address Load Owns Host ID Token Rack
UN 10.1.10.75 144.43 MB 60.0% 9bac71dd-1faf-42c8-a26c-d8fff47abf15 0 RAC1
UN 10.1.10.78 168.48 MB 2.5% c9175995-54dd-4ef2-a4d1-5472d46d8477 2767011611056432740 RAC1
UN 10.1.10.79 152.05 MB 2.5% 69c545ba-716c-4b51-92c1-760063addf00 3689348814741910320 RAC1
UN 10.1.10.76 41.34 MB 0.0% 3d24f678-e3bf-42b0-b4b9-47346e290310 3689348814741910322 RAC1
UN 10.1.10.77 51.81 MB 10.0% 796b196b-6f19-4479-a678-021fa472e107 7378697629483820644 RAC1
Datacenter: DC2
===============
Status=Up/Down
|/ State=Normal/Leaving/Joining/Moving
-- Address Load Owns Host ID Token Rack
UN 10.1.10.80 127.16 MB 2.5% 11b62771-319a-4afd-aeef-40854577d56a 461168601842738790 RAC1
UN 10.1.10.82 149.95 MB 10.0% ee7ddb5e-fe89-4faa-bab6-e5cb33501fd9 2305843009213693950 RAC1
UN 10.1.10.83 146.12 MB 2.5% 7cdc6a59-577f-4b00-a217-c9e5bb5cd77e 3228180212899171530 RAC1
UN 10.1.10.84 23.07 MB 2.5% 64c545c6-e82f-4983-b36b-1bfeed88af1e 4150517416584649110 RAC1
UN 10.1.10.81 18.36 MB 7.5% 0c61d2a2-c255-48fe-b2e3-fac4670c008f 5534023222112865483 RAC1
Вопрос номер 1) Как сбалансировать кластер?
2) Почему данные не размазываются равномерно?
3) Мы тестируем cassandra 1.2 и максимальный токен 2^63, а не 2^123. Ноды просто не запускаются с токеном, значение которого больше чем 2^63 (Java Exception). Неужели они уменьшили токен, но все еще не обновили документацию?
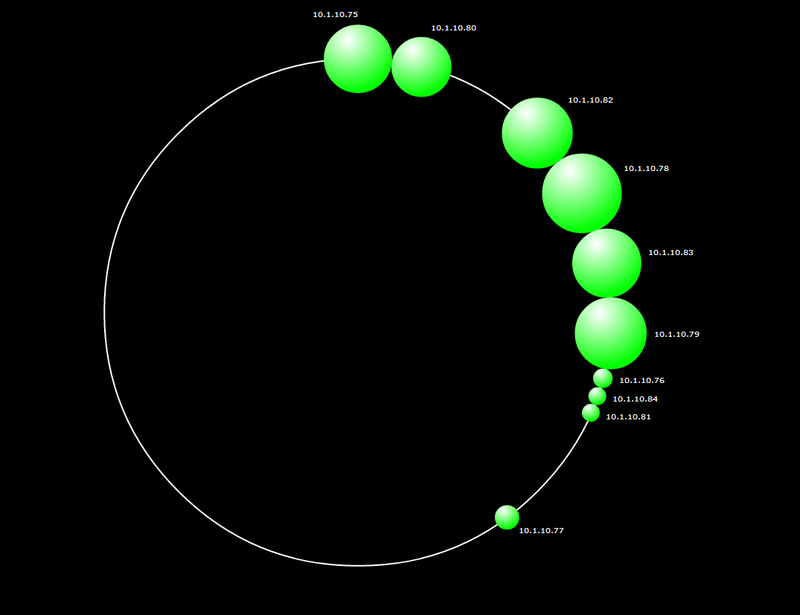
Вот еще пара скриншотов для затравки
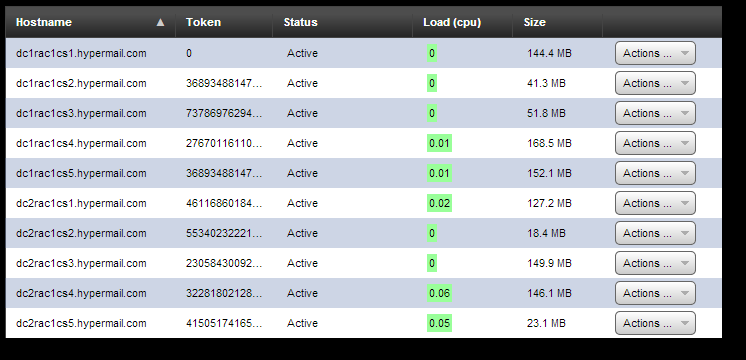
P.S.: Если человекам будет интересно, я могу запустить несколько бенчмарков и позже написать статью о том, как мы подняли этот кластер и все результаты бенчмарковю
UPD: Проблема с токенами решена. В Cassandra начиная с версии 1.2 токен не от 0 до 2^126, а -2^63 До +2^63.
www.datastax.com/docs/1.2/initialize/token_generation
Сейчас попытаемся пересоздать токены и посмотрим, что будет.