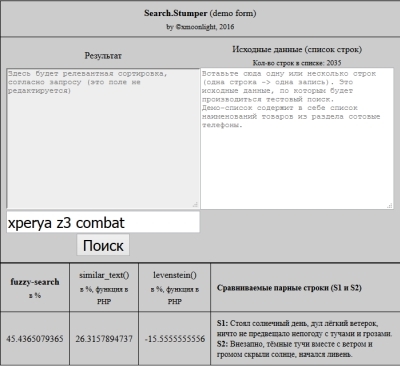
Прошу вашей помощи в решении задачи. Подсказать направление куда "копать".
Имеется список строк. Длина строки 2-7 слов. В этих строках написаны названия различных приложений. Строки часто составлены или с ошибками, или с лишними словами, или короче, чем оригинальное название.
Например, " Система для документов Программуля" вместо " Программуля плюс документс".
То есть в этих строках сохраняется некая суть правильного названия.
Имеется база (список) правильных названий программ.
Необходимо сверить два списка, чтобы понять есть ли искомые строки в базе, если есть, то как они правильно называются, если нет в базе, то понять это.
Дословное сравнение не сработает, потому что искомые строки составляют люди, которые могут ошибиться.
Подумал о том, чтобы проверить строки на "похожесть". Тут и застопорился.
Есть проверка слов на похожесть через алгоритмы нечеткого поиска. Не совсем понятно, какие лучше.
Не до конца понимаю то, как понять что целое предложение(набор слов) похоже на другое предложение.
Прошу помочь советом. Не жду готовых решений (разве что чего-то похожего для примера). Подскажите куда "копать", как выстроить алгоритм?
Буду реализовывать на языке Java.
UPD: набрел на одну тему, где использовался алгоритм нечеткого сравнения для сравнения слов из предложения со словарем правильных слов.
Проводили индексацию предложения, выстраивали массив встречающихся слов и связей с другими словами. Дальше не объясню, не совсем понимаю.
Что такое индексация? Как она помогает в поиске целого предложения по отдельным словам.
Не, вы не то просите. Похожесть строк это когда две строки.
А вы будете брать одно строку из одного множества, и ранжировать(сортировать) по релевантности к ней второе множество.
Т.е. у вас строка и множество строк это не тоже самое, что две строки.
Возьмите сфинкс, вы там получите несколько типов(алгоритмов) совпадений и подбирая коэффициенты придумаете формулу для ранжирования.
Индексация нужна, что всё тормозило один раз при индексации, а не при поиске каждого совпадения.
Спасибо за комментарий. Я правильно понял, что я беру строку, беру некий список и сортирую его так, чтобы "вверху" списка были наиболее похожие строки? Или делаю новый список со ссылками настроки из списка-словаря. Так?
А насчет индексации. Видел некоторые пояснения на хабре о том, как делается индекстиз списка строк. Не совсем понятно каким образом этот индекс участвует в поиске и ранжировании? Могли бы пояснить или указать на источник с информацией?
Я не очень понял что вы хотите уточнить в первом абзаце. У вас же два списка, поэтому вам в любом случае брать один элемент из первого списка и сравнивать (т.е. искать наиболее похожие) с всеми элементами второго списка. В итоге для каждой сравниваемой пары у вас будет некоторое число по которому вы будете сортировать весь список с которым сравниваете фразу. Соответственно на верху списка будут наиболее подходящие варианты.
Вам не стоит закапываться в реализации самих алгоритмов, вы просто берёте популярный поисковый движёк, например sphinxsearch (это отдельное приложение) или lucene (библиотека на java) строите в нём поисковый индекс, дальше просто будете экспериментировать с разными типами поисковых запросов пока не добьётесь результата. Я полагаю у вас сходу точность должна быть около 90%
Что бы была ближе к 100%, и лучше с исправлением ошибок и опечаток можно экспериментировать с N-граммамми, частотностью букв и слогов в языке, получая дополнительные варианты фразы от той строки, что будете искать по списку. А можно просто тупо дёрнуть spellcheker для получения тех же вариантов.
Вы когда попробуете готовый поисковый движок, посмотрите результат, у вас уже будут конкретные вопросы на которые будет легко найти ответы. Не копайте в глубь сейчас, просто пробуйте.
Walt Disney: Спасибо за комментарий и за названия библиотек. И правда начинаю закапываться вглубь, хотя сейчас это не требуется. ( чем глубже, тем страшней).
[У вас же два списка, поэтому вам в любом случае брать один элемент из первого списка и сравнивать (т.е. искать наиболее похожие)] - в данном случае возникает вопрос похожести. Тут я уже либо пользуюсь некими алгоритмами расстояния, либо пилю свой способ на свое усмотрение. Так получается?
Walt Disney: Вот оно что. :) Спасибо большое за ответ.
Теперь пойду разбираться с библиотекой. В любом случае любопытно как делается индексация списка строк ( для личного развития), и понять как потом в индексируемом словаре осуществляется поиск.
Но это уже тема отдельного вопроса.
Не, вы не то просите. Похожесть строк это когда две строки.
А вы будете брать одно строку из одного множества, и ранжировать(сортировать) по релевантности к ней второе множество.
Т.е. у вас строка и множество строк это не тоже самое, что две строки.
-----
Простите, но это одно и то же... Т.к. ранжировать множество по релевантности вы всё равно будете по-поэлементно.
Кстати, если интересно то скоро смогу выложить линк на свой "живой" пример.
xmoonlight: Конечно, интересно. Я сейчас делаю свой проект теми средствами, которые понял на данный момент. Мне будет очень интересно посмотреть работающие другие варианты.
xmoonlight: Одно и тоже будет в самом простом случае, когда есть только одна метрика сравнения, т.е. будет только один проход. Но даже это утверждение спорно при наличии индекса, т.е. индекс это множество, но служит для оптимизации только одного типа сравнений.
У меня на таких задачах получается 5-10 проходов из них половина для расчёта релевантности, половина для подготовки данных для индекса и/или "нормализации" поискового запроса.
Walt Disney: Что-то наподобие нескольких уровней сита. Каждый просеивает общую кучу. Идея понятна, но реализация и как применяется, по каким факторам отсеивает пока не очень :)
Walt Disney: Демо есть где-нить живьём? И действительно: по каким факторам ранжирует? Это поиск по сайту или что-то еще? Артур: Прошу прощения за задержку. Вход в свою демку планирую сегодня доделать и тогда скину линк на почту.
xmoonlight: в демо нет смысла
У автора что то типа:
Сырая - "Яндекс браузер", эталонная - "Yandex браузер"
1-й "яндекс диск" 0.65, "yandex браузер" 0.45 - первый выше т.к. яндекс более уникальное слово
2-й прогоняем через soundex, "яндекс диск" 0.4, "yandex браузер" 0.9
ранжирование: "yandex браузер" 0.45+0.9 = 1.35, "яндекс диск" 0.65+0.4= 1.05
А если на верхушке меньше 0.5, считаем, что ошибка в исходной фразе, строим N гипотез какая могла быть фраза и ищем каждую.
т.к. мы понимаем, что dDisc нормальное название для программы, а вот алгоритмы исправления не очень, то смотрим отдельно прямые вхождения каждого слова (а может тут будет достаточно результатов первого прохода, это экспериментально)
и получаем формулу ранжирования типа:
к1*р1+к2*р2+к3*р3 ,где к это подбираемые коэффициенты, р1 - ранк из первого поиска, р2 - вероятность правильности гипотезы * ранк поиск этой гипотезы, р3 - ранк прямых вхождений
Автору надо просто начать, если у него интерфейс модератора то ему хватит и одного прохода который дают библиотеки из коробки, заморочки начинаются когда начинаем стремится к 100%.
Walt Disney: Откуда берется коэффициент 0.65 в
"
У автора что то типа:
Сырая - "Яндекс браузер", эталонная - "Yandex браузер"
1-й "яндекс диск" 0.65, "yandex браузер" 0.45 - первый выше т.к. яндекс более уникальное слово
2-й прогоняем через soundex, "яндекс диск" 0.4, "yandex браузер" .........
"
?
Из чего он строится?
Владимир, спасибо за ответ. Я так понимаю, что алгоритм нечеткого сравнения идет для слов, а как быть для строки? Выдумать свой собственный алгоритм (читай велосипед) на основе полученных данных о словах?
Пришел к тому, что хорошо бы освоить Apache Lucene.
Тот способ поиска, который был у меня самопальный, работал "не так чтобы очень".
Много "допиливаний" требовалось по различным неточностям.
Но. Есть пару "но". Создание самопального продукта позволило более детально изучить вопрос поиска, поисковых систем, разбиения на токены и индексацию.
Так что все было отлично.
Пробуйте свои идеи. Даже если не пойдет, приобретете опыт.





 Средний
Средний