Подскажите пожалуйста как правильно осуществить слияние двух датафрэймов
In [1]: df1 = pd.DataFrame({'A': ['A0', 'A1', 'A2', 'A3'],
...: 'B': ['B0', 'B1', 'B2', 'B3'],
...: 'C': ['C0', 'C1', 'C2', 'C3'],
...: 'D': ['D0', 'D1', 'D2', 'D3']},
...: index=[0, 1, 2, 3])
In [2]: df2 = pd.DataFrame({'A': ['A4', 'A5', 'A6', 'A7'],
...: 'B': ['B4', 'B1', 'B2', 'B7'],
...: 'C': ['C4', 'C1', 'C2', 'C7'],
...: 'D': ['D4', 'D5', 'D6', 'D7']},
...: index=[0, 1, 2, 3])
Необходимо выполнить слияние так, что-бы строки которые имеют хоть по одному одинаковому элементу заменились на строки в первом датафрэме строками из второго датафрэйма, а у тех у которых совпадений не найдено просто добавились в конец первого же датафрэйма.
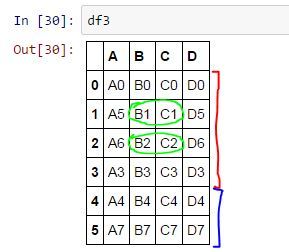
таблица 1 и таблица2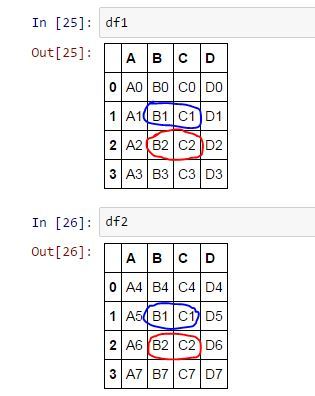 в итоге необходимо получить
в итоге необходимо получить