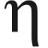Задача стоит следующая. Есть файл примерно окало 50-70тс строк, строки разной длины.
Нужно взять случайную строку из файла, но при этом сам файл не загружать в поток. так как его размер 150метров. а нужна одна случайная строка.
Были попытки передвигать внутренний указатель файла на количество байт.
Но так как строка разная, то может возятся 2 строки куском.
Чет я прегрустнул, в голову вообще не чего не лезет. Может кто знает или сталкивался?
Если нельзя загнать данные в базу, то могу предложить велосипед-костыль. Можно построить индекс (файл с парами смещение: длина, данные выровнять) и использовать его для доступа к строкам.
Зачем человеку парсить файл полностью, если нужна всего одна строка? Не проще ли пропарсить одну строку начиная со случайного места + некий мусор от этого случайного места до следующей строки?
@taliban, я не предлагаю каждый раз парсить файл полностью. Всего 1 раз строится индекс, сохраняется в файл, далее используются эти данные. Это позволяет предсказуемо просто получить доступ к любой строке по её номеру (первый плюс). И нет необходимости каждый раз парсить файл в поисках подходящего фрагмента-строки (что в некоторых случаях может быть медленнее, чем использование индекса).
Можно сказать что это два альтернативных решения. Всему своё время и место.
Справедливости ради стоит заметить что получить случайную строку можно и без использования индекса, алгоритмов (вариант shsweb), лишь используя стандартные средства php. Вариант без индекса.
Вариант с индексом (1000 запусков)
real 0m43.108s
user 0m26.154s
sys 0m14.333s
Вариант без индекса (1000 запусков)
real 0m43.902s
user 0m26.150s
sys 0m14.161s
Потребление памяти в обоих случаях ~0.31-0.32mb.
Итог: потребление памяти и время выполнения примерно одинаковое.
Речь идет про програмный метод? Если да, то можно взять случайный указатель где-то внутри файла и потом найти ближайший "\n" (или какой там указатель конца строки), а потом взять кусок от этого до следующего указателя конца строки (или конца файла если это вдруг последняя строчка).
1. Единожды пропарсить файл на предмет поиска максимальной длины строки, Получить MaxLen.
2. Сгенерировать случайный указатель внутри файла
3. Считать блок (2*MaxLen+2 перевода строки) из файла
4. Найти в нем строку между "\n" и "\n"
5. Выдать строку.
1. Берете случайную позицию от 0 до <file_length>
2. Считываете по байту пока не наткнетесь на \n
3. Считываете по байту в некий буфер пока не наткнетесь на \n
4.!!!
5. PROFIT!
taliban примерно правильно описал. Я бы только не по байту считывал, а сразу блоками (и внутри блока искал), а то иначе слишком уж медленно будет работать.
Строка это текст от начала файла или символа \n и до конца файла или символа \n (смотря что первей). А случайная строка это какая либо из строк в определенном файле.
Я бы определил максимально возможную длину строки и в произвольном месте (fseek) читал бы двойную длину (fread). И потом уже в полученном фрагменте искал бы строку, ограниченную двумя переводами строки или даже sscanf'ом.
А зачем что-то искать если родные функции PHP отлично все найдут за вас.
Делаете fseek в случайное место файла. Делаете первый fgets() или stream_get_line() c достаточным размером буфера — они гарантированно сами найдут конец строки. Далее делаете fseek от первоначального места + считанная длина строки — т.е. гарантированно попадаете на начало след. строки, которой делаете fgets() и используете.
(Нужно добавить проверки на EOF конечно)
Таким образом вы получите свою строку ценой памяти занятой буфером fgets/stream_get_line и все.
По-моему даже второй fseek не нужно делать, так как fgets/stream_get_line выйдут когда найдут конец строки, а значит указатель файла будет на начале след. строки.









 Средний
Средний