что то вы все всё намудрили, запросы, ридонли, контексты
можешь запустить несколько инстансов - запускай, пусть разгребают очередь
не можешь - запускай один, и пусть он же и разгребает
в чем проблема? тут нет ничего нового, это обыкновенная CLI-программа
например пришло два промпта, и одновременно два и обрабатывается сразу на одной машине. Вот например та же LLaMA.cpp
два инстанса - два промпта, либо настолько быстрая генерация, что кажется, что они выполнились одновременно
нет там никакой алгоритмической магии, просто большой вычислительный ресурс, нет никаких параллельных потоков, любой параллельный поток это просто другой инстанс, оно просто с архитектурной точки зрения не предназначено работать параллельно, это тебе не квантовая суперпозиция
про контексты и сеансы что то
Иерокопус Таманский вообще завернул, это вопроса не касается никак и ты в целом простое решение сложными словами описал, не очевидно что бекенд должен куки с сессиями и контекстами разруливать? оно же из формулировки вопроса уже - многопользовательское
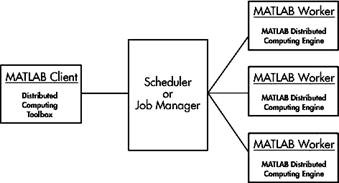
вот тебе принципиальная схема на примере чего-то другого. слева - UI, центр - очередь запросов на генерацию, справа - инстансы, слово "matlab" просто мысленно замажь