Только познакомился с парсингом. Просмотрел видеоурок и реализовал такой код:
import requests
from bs4 import BeautifulSoup as BS
r = requests.get('https://www.igromania.ru/games/')
html = BS(r.content, 'html.parser')
for el in html.select('.CommonBasePage_page__mlC3i > .CommonBasePage_page_content__o0c0C'): #.d-flex app main-chat > .main dialog custom-scrollbar > .chat-request flex-row-reverse gap-10 > .chat-infor align-flex-start >
title = el.select('.GameCard_content__5G7vA > a')
for i in title:
print(i.text)
Теперь мне надо реализовать что-то похожее для другого сайта
ссылка на сайт
Вот что я написал:
import requests
from bs4 import BeautifulSoup as BS
r = requests.get('https://talkai.info/ru/chat/')
html = BS(r.content, 'html.parser')
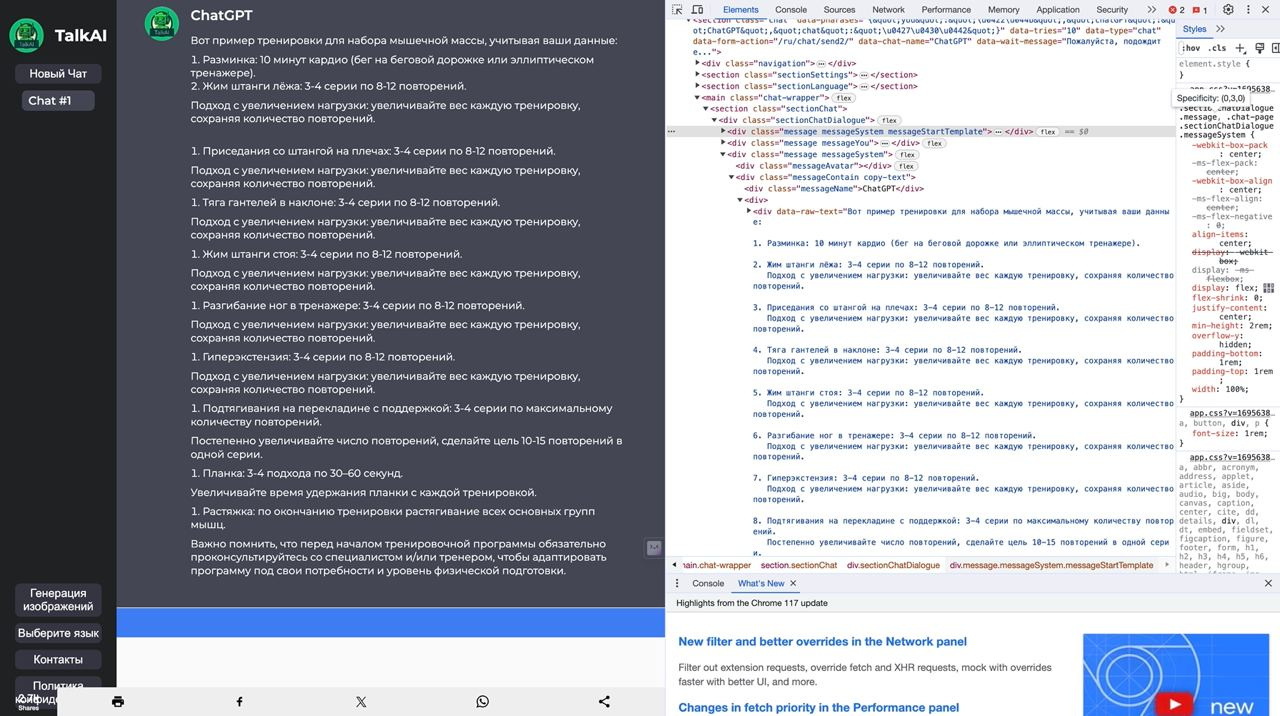
for el in html.select('.sectionChat > .sectionChatDialogue'): #.d-flex app main-chat > .main dialog custom-scrollbar > .chat-request flex-row-reverse gap-10 > .chat-infor align-flex-start >
title = el.select('.messageContain copy-text')
for i in title:
print(i.text)
Проблема в том, что не заходит программа в цикл и как я понял проблема с селектором.
Может кто подсказать как правильно использовать селекторы?
Вот фото кода сайта




 Простой
Простой

