def process(train, categories):
cats = categories
cats.append('full')
mux = pd.MultiIndex.from_product([['Count', 'TF', 'TF-IDF'],['Без стоп-слов', 'Со стоп-словами']])
summary = dict()
for category in cats:
summary[category] = pd.DataFrame(columns=mux)
stop_words = [None, 'english']
idf = [False, True]
indx_stop = {
'english': 'Без стоп-слов',
None: 'Со стоп-cловами'
}
indx_tf = {
False: 'TF',
True: 'TF-IDF'
}
for category in cats:
for stop in stop_words:
vect = CountVectorizer(max_features=10000, stop_words=stop)
vect.fit(train[category])
train_data = vect.transform(train[category])
summary[category]['Count', indx_stop[stop]] = top_list(vect, train_data, 20)
for tf in idf:
tfidf = TfidfTransformer(use_idf = tf).fit(train_data)
train_fidf = tfidf.transform(train_data)
summary[category][indx_tf[tf], indx_stop[stop]] = top_list(vect, train_fidf, 20)
return summary
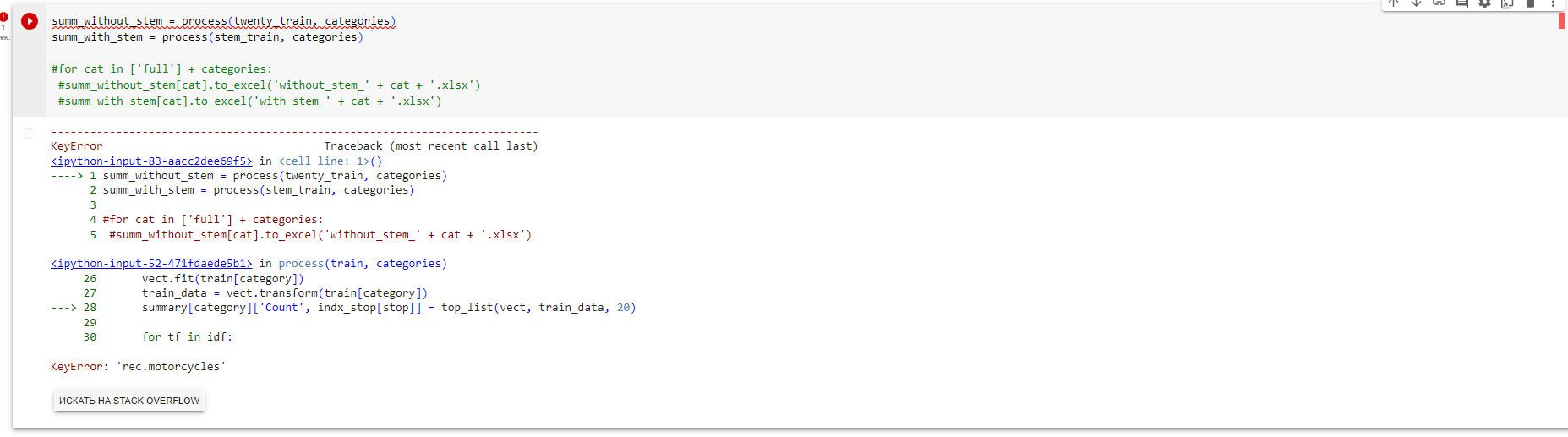
Как исправить ошибку (на скрине)?
Ошибка:
---------------------------------------------------------------------------
KeyError Traceback (most recent call last)
<ipython-input-86-aeec6dd651b6> in <cell line: 1>()
----> 1 summ_without_stem = process(twenty_train, categories)
2 summ_with_stem = process(stem_train, categories)
3
4 for cat in ['full'] + categories:
5 summ_without_stem[cat].to_excel('without_stem_' + cat + '.xlsx')
<ipython-input-52-471fdaede5b1> in process(train, categories)
26 vect.fit(train[category])
27 train_data = vect.transform(train[category])
---> 28 summary[category]['Count', indx_stop[stop]] = top_list(vect, train_data, 20)
29
30 for tf in idf:
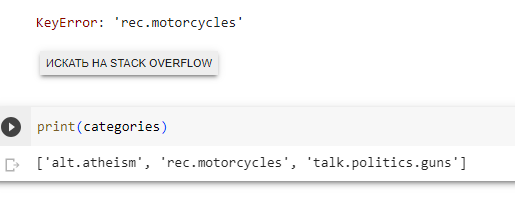
KeyError: 'rec.motorcycles'






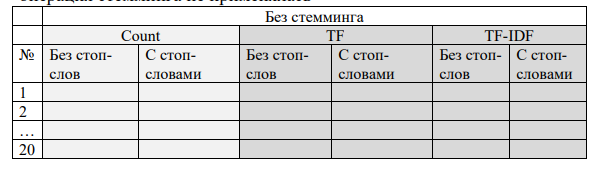 такого типа внутри каждого большого индекса, то есть, таких табличек 4 (cat1 - cat3, full) (прошу прощения за такие слова, но я больше по С/С++, чем python)
такого типа внутри каждого большого индекса, то есть, таких табличек 4 (cat1 - cat3, full) (прошу прощения за такие слова, но я больше по С/С++, чем python)  Вот так выглядит каждое значение твоего словаря (фрейм), которые ты пытаешься заполнить, это что бы ты понимал что происходит. Это к слову о декомпозиции.
Вот так выглядит каждое значение твоего словаря (фрейм), которые ты пытаешься заполнить, это что бы ты понимал что происходит. Это к слову о декомпозиции. 
