Сейчас есть монолит, в котором в Quartz.NET крутятся задачи, которые хотелось бы вынести в отдельные микросервисы.
Например возьмем сущность MeteringDevice (какой-то прибор измерения). Для него в отдельной базе для Quartz'a есть таблица (import_md): id (int), request_id (int null), md_id (int), result (varchar null), is_error (bit). В данный момент работает импортирование так, что 1 задача в Quartz лезет в эту таблицу, берет от туда 100 записей в порядке очереди и импортирует приборы, но приборов в моменты времени может быть очень много и 1 задача попросту начинает делать это всё очень долго.
Хотелось бы как-то разбить это на микросервисы, чтобы в случае пиковых нагрузок можно было поднять еще 3-4 этих микросервиса и разделить нагрузку импорта сразу в несколько машин.
Как это лучше сделать? Т.к. запросы на импорт могут быть вызваны не только с Gateway API, но и из самой базы (отдельной Quartz задачей).
Есть ли смысл сделать так: main gateway api -> database. metering device producer (в нем и будут задачи на хождение в базу) -> rabbitmq -> -> services?
То есть, metering device producer забрал из таблицы import_md 100 записей, отправил их в RabbitMQ, а уже сами микросервисы будут делать всю дальнейшую работу (импортировать, обновлять запись в базе (проставить result, is_error)).
И как быть с перезапуском сервисов? Дубликаты запросов на импорт нельзя делать, значит нужно, если запрос на сервисе ушел, то запись про это в базе появилась точно.
В данный момент всё работает так: server + quartz -> db -> внутренняя программа (proxy) -> remote api, remote api отдает id запроса, который складываем в БД, чтобы потом другая задача в Quartz сходила и сделала запрос ответа по ранее выданному id.
Так же еще важный момент, что для импорта данных нужно сначала сделать экспорт с api.
Как вижу схему:
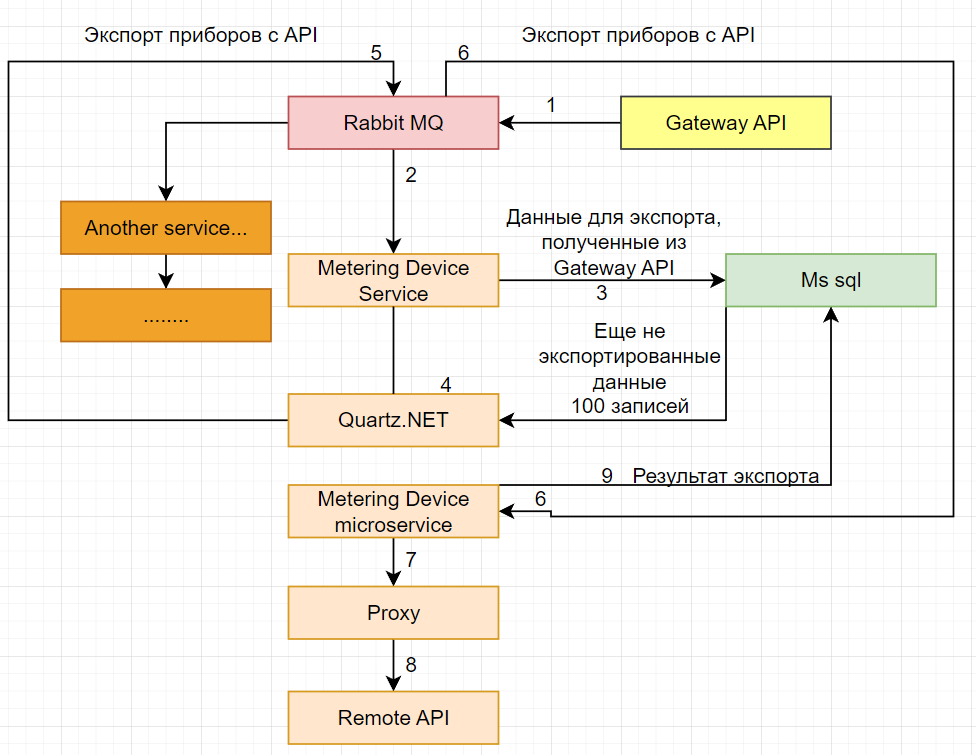
Соответственно потом импорт будет точно так же делать, сначала Quartz заберет 100 записей, кинет их в Rabbit, их обработают микросервисы и положат результат в базу сами.
Возможно, что в такой схеме Metering Device service лишний (в этой схеме он и producer, и consumer(!)) и сам gateway api может писать в базу, но как раз и хотелось убрать эту задержку при работе с базой, чтобы ответ от API был минимальный.
Вариант 2: в этой схеме избавиться от Quartz, чтобы в базу писались данные, а потом сразу уходил пуш в rabbit.

 Простой
Простой
 Простой
Простой




