Мне нужно часто делать запрос на один url (каждые 10 сек), но сайт после 3-4 запросов меня блочит и дает 429, пробовал менять ip для каждого запроса с помощью tor, но не помогло.
Вот код:
ua = UserAgent()
SOCKS_PORT = 9050
TOR_PATH = os.path.normpath(os.getcwd()+"\\Tor\\tor\\tor.exe")
tor_process = stem.process.launch_tor_with_config(
config = {
'SocksPort': str(SOCKS_PORT),
'StrictNodes' : '1',
'CookieAuthentication' : '1',
'MaxCircuitDirtiness' : '10',
'GeoIPFile' : 'https://raw.githubusercontent.com/torproject/tor/main/src/config/geoip'
},
init_msg_handler = lambda line: print(line) if re.search('Bootstrapped', line) else False,
tor_cmd = TOR_PATH
)
PROXIES = {
'http': 'socks5://127.0.0.1:9050',
'https': 'socks5://127.0.0.1:9050'
}
url = 'https://steamcommunity.com/market/listings/730/AWP%20%7C%20Atheris%20%28Minimal%20Wear%29/render/?query=&start=0&count=100¤cy=18'
for i in range(10):
response = requests.get("http://ip-api.com/json/", proxies=PROXIES)
result = response.json()
print('TOR IP [%s]: %s %s'%(datetime.now().strftime("%d-%m-%Y %H:%M:%S"), result["query"], result["country"]))
headers = {
'User-Agent': ua.random
}
resp_test = requests.get(url, proxies=PROXIES, headers=headers)
print(resp_test)
time.sleep(11)
tor_process.kill()
Вывод:
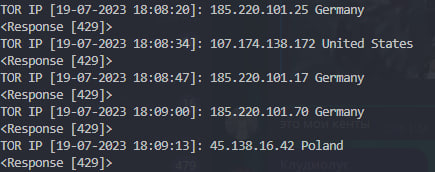
Подскажите как решаются такие проблемы, может нужен платный прокси или как?





