

import pandas as pd
# Создаем DataFrame с данными
data = {'Шифр дисциплины': ['ОГСЭ.02', 'ОГСЭ.03', 'ОГСЭ.04', 'ОГСЭ.05', 'ЕН.01', 'ОПЦ.01', 'ОПЦ.02', 'ОПЦ.03', 'ОПЦ.08', 'ОГСЭ.01', 'ОГСЭ.02', 'ОГСЭ.04', 'ОГСЭ.05', 'ЕН.02', 'ОПЦ.04', 'ОПЦ.11', 'ОПЦ.13', 'МДК.01.01', 'ПМ.02.01(К)', 'МДК.02.01', 'МДК.02.02', 'МДК.02.03', 'УП.02.01', 'ПП.02.01'],
'Курс': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
'Семестр': [1, 1, 1, 1, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2]}
df = pd.DataFrame(data)
# сортируем DataFrame по столбцам "Шифр дисциплины", "Курс", "Семестр"
df_sorted = df.sort_values(by=['Шифр дисциплины', 'Курс', 'Семестр'], kind='mergesort')
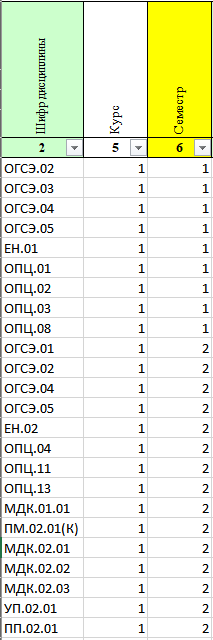
print(df_sorted)Шифр дисциплины Курс Семестр
4 ЕН.01 1 1
13 ЕН.02 1 2
17 МДК.01.01 1 2
19 МДК.02.01 1 2
20 МДК.02.02 1 2
21 МДК.02.03 1 2
9 ОГСЭ.01 1 2
0 ОГСЭ.02 1 1
10 ОГСЭ.02 1 2
1 ОГСЭ.03 1 1
2 ОГСЭ.04 1 1
11 ОГСЭ.04 1 2
3 ОГСЭ.05 1 1
12 ОГСЭ.05 1 2
5 ОПЦ.01 1 1
6 ОПЦ.02 1 1
7 ОПЦ.03 1 1
14 ОПЦ.04 1 2
8 ОПЦ.08 1 1
15 ОПЦ.11 1 2
16 ОПЦ.13 1 2
18 ПМ.02.01(К) 1 2
23 ПП.02.01 1 2
22 УП.02.01 1 2import pandas as pd
data = {'Шифр дисциплины': ['ОГСЭ.02', 'ОГСЭ.03', 'ОГСЭ.04', 'ОГСЭ.05', 'ЕН.01', 'ОПЦ.01', 'ОПЦ.02', 'ОПЦ.03', 'ОПЦ.08', 'ОГСЭ.01', 'ОГСЭ.02', 'ОГСЭ.04', 'ОГСЭ.05', 'ЕН.02', 'ОПЦ.04', 'ОПЦ.11', 'ОПЦ.13', 'МДК.01.01', 'ПМ.02.01(К)', 'МДК.02.01', 'МДК.02.02', 'МДК.02.03', 'УП.02.01', 'ПП.02.01'],
'Курс': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
'Семестр': [1, 1, 1, 1, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2]}
df = pd.DataFrame(data)
# Получаем список и порядок уникальных значений шифров
order = list(df['Шифр дисциплины'].str.split('.').str.get(0).unique())
categories = pd.CategoricalDtype(categories=order, ordered=True)
df['temp'] = df['Шифр дисциплины'].str.extract('(\w+)', expand=False).astype(categories)
df = df.sort_values(by='temp')
df = df.drop(columns='temp')
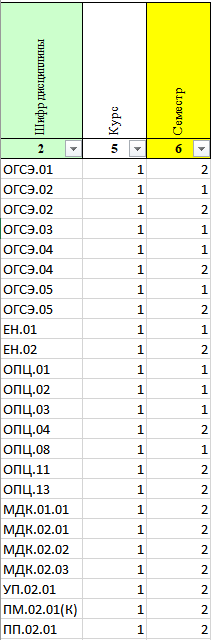
print(df)Шифр дисциплины Курс Семестр
0 ОГСЭ.02 1 1
12 ОГСЭ.05 1 2
10 ОГСЭ.02 1 2
9 ОГСЭ.01 1 2
11 ОГСЭ.04 1 2
3 ОГСЭ.05 1 1
2 ОГСЭ.04 1 1
1 ОГСЭ.03 1 1
4 ЕН.01 1 1
13 ЕН.02 1 2
5 ОПЦ.01 1 1
16 ОПЦ.13 1 2
15 ОПЦ.11 1 2
14 ОПЦ.04 1 2
8 ОПЦ.08 1 1
7 ОПЦ.03 1 1
6 ОПЦ.02 1 1
17 МДК.01.01 1 2
19 МДК.02.01 1 2
20 МДК.02.02 1 2
21 МДК.02.03 1 2
18 ПМ.02.01(К) 1 2
22 УП.02.01 1 2
23 ПП.02.01 1 2
cat = pd.Categorical(df['Шифр дисциплины'].str.split('.').str[0],
categories=['ОГСЭ','ЕН','ОПЦ','МДК','УП','ПМ','ПП'])
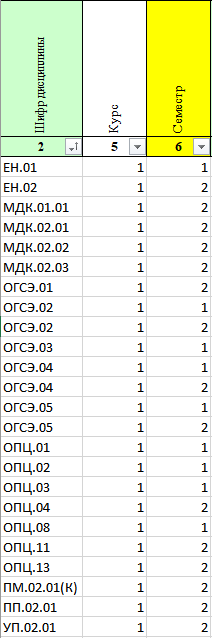
print(df
.groupby(cat)
.apply(lambda x: x.sort_values('Шифр дисциплины', key = lambda x: x.str.split('.').str[1]))
.reset_index(drop=True)
)cat = pd.Categorical(df['Шифр дисциплины'].str.split('.').str[0],
categories=['ОГСЭ','ЕН','ОПЦ','МДК','УП','ПМ','ПП'])
df.sort_values(by=['Шифр дисциплины'],key= lambda x: cat) Средний
Простой
Средний
Простой

