

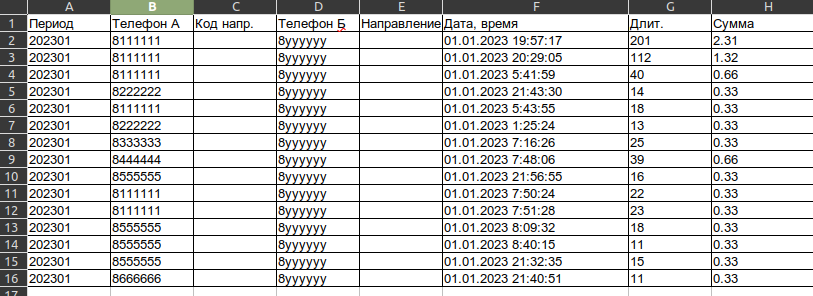

df = pd.read_excel('Твой Файл')
df.groupby('Телефон A')['Сумма'].sum()
 Простой
Простой
 Простой
Средний
Простой
Средний
 Простой
Средний
Простой
Средний
 Средний
Простой
Средний
Простой
