Всем привет
Хочу спарсить логины людей которые выставляют свои нфт на продажу
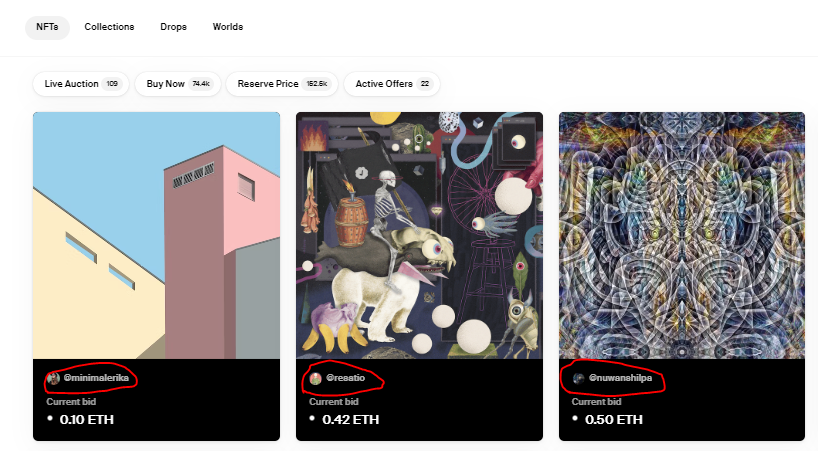
Пробовал различные способы которые были описаны в похожих темах и на ютубе, ничего не помогает, может кто то мог бы подсказать решение.
Вот примеры того какие способы пробовал:
Через обращение к graphql -
<скрины> |
<текст ошибки>
Также пробовал сначала сохранить каскад и дальше нужно было делать махинации с запросами но сохранялся зачастую или пустой документ или код json -
<ссылка>
Ну и метод
с этой темы, подставлял данные на свои но код выдавал ошибки.
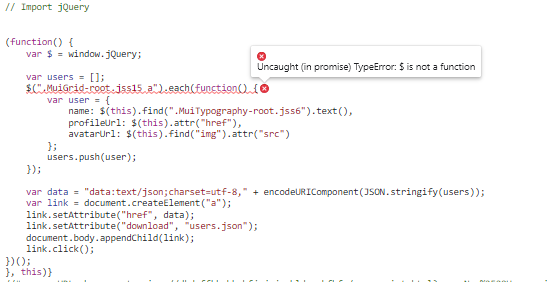
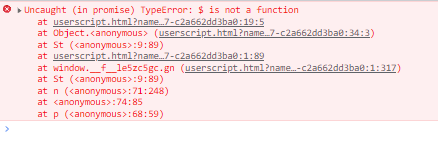
По совету одного из комментаторов попробовал сделать инжект скрипта с помощью плагина tempermonkey но не могу разобраться с селектором
<скрины>
ps. может у кого то будут болеть глаза от кода, искал способы как мог, буду благодарен за любую помощь.

 Сложный
Сложный